Code
# A tibble: 2 × 2
Class n
<fct> <int>
1 benign 444
2 malignant 239November 20, 2025
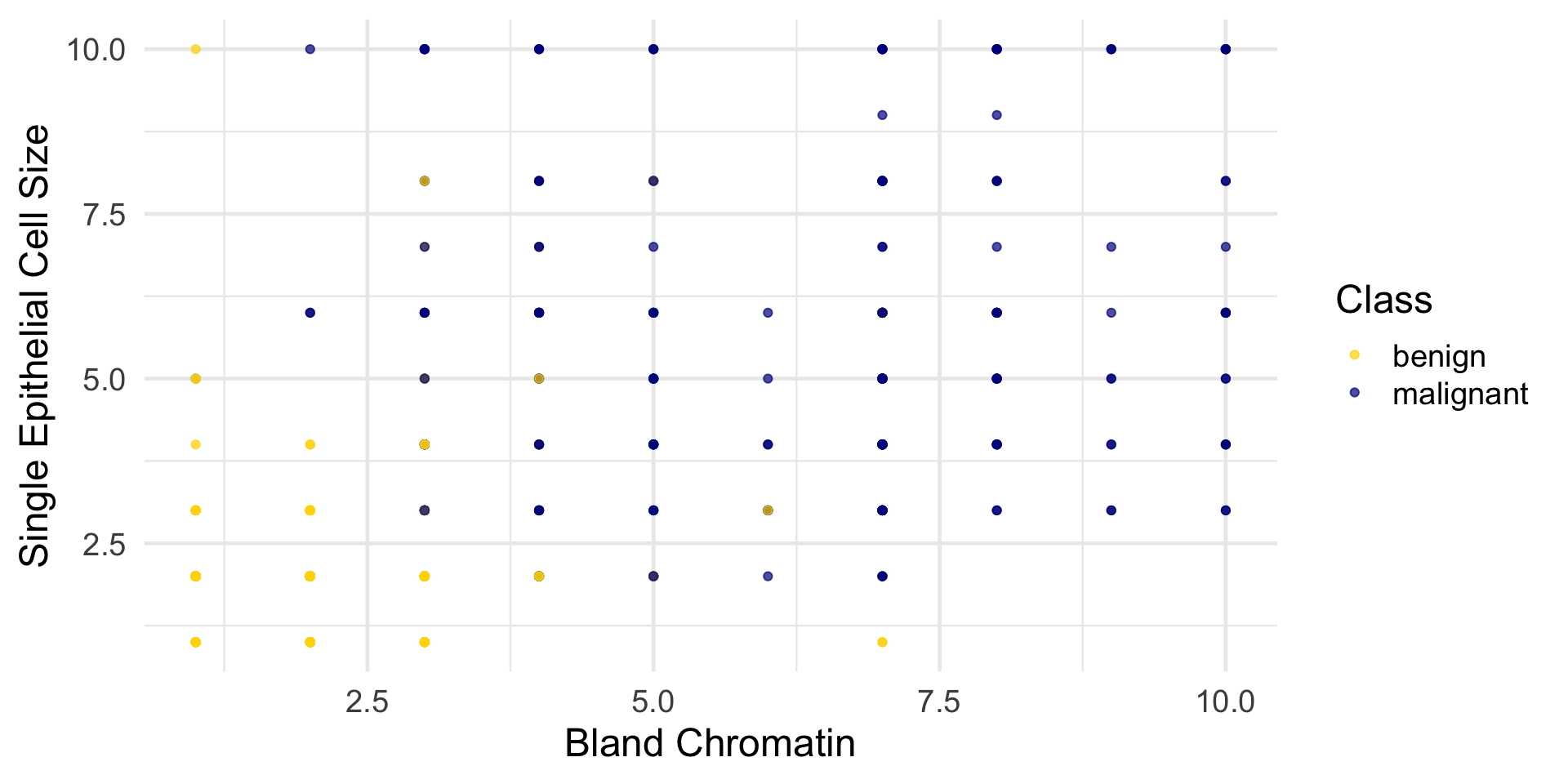
Our dataset contains attributes for cancer diagnosis: malignant (cancer) or benign (not cancer).
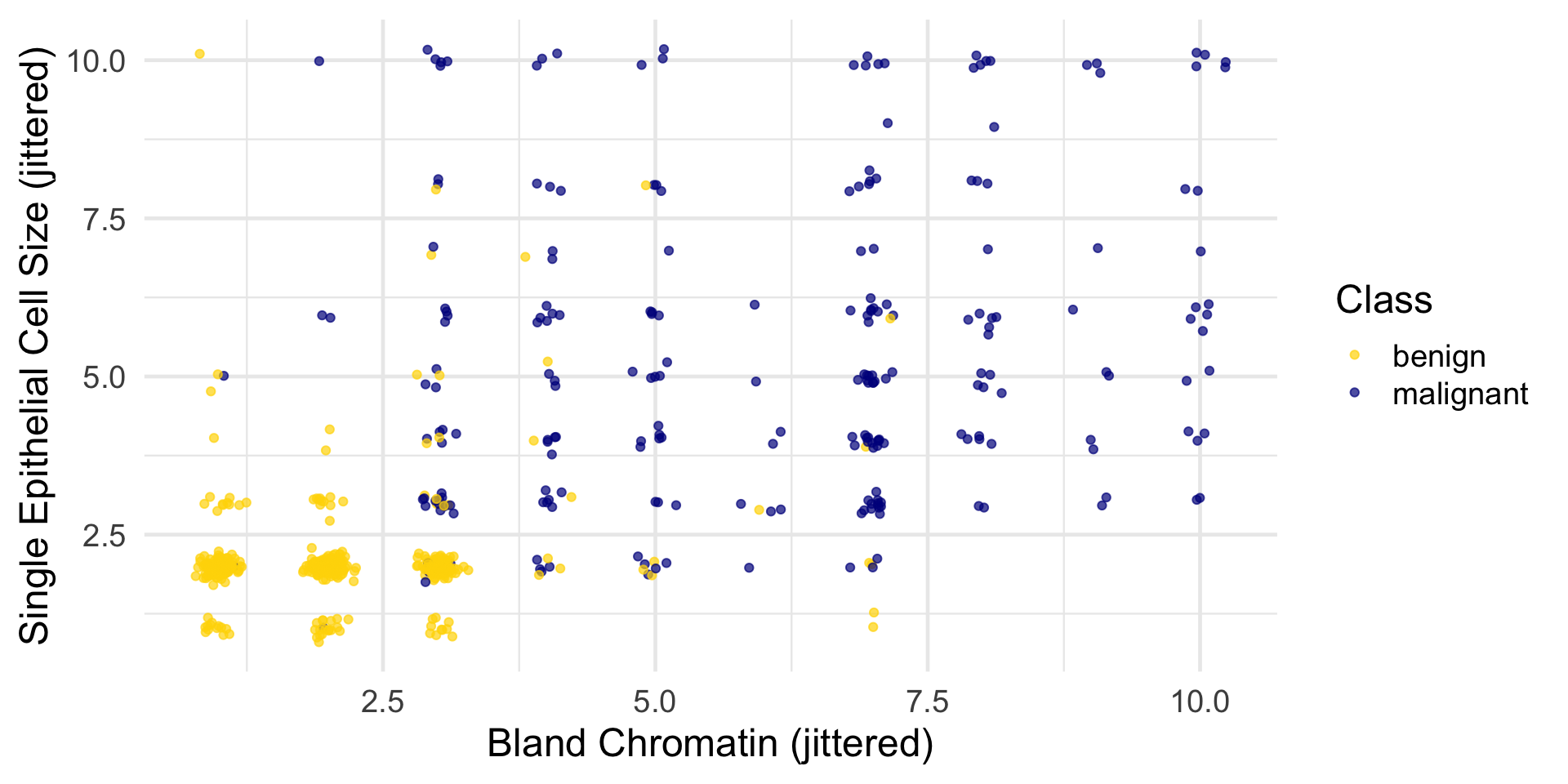
The jittering is just for visualization; we’ll use the original (unjittered) data for modeling.
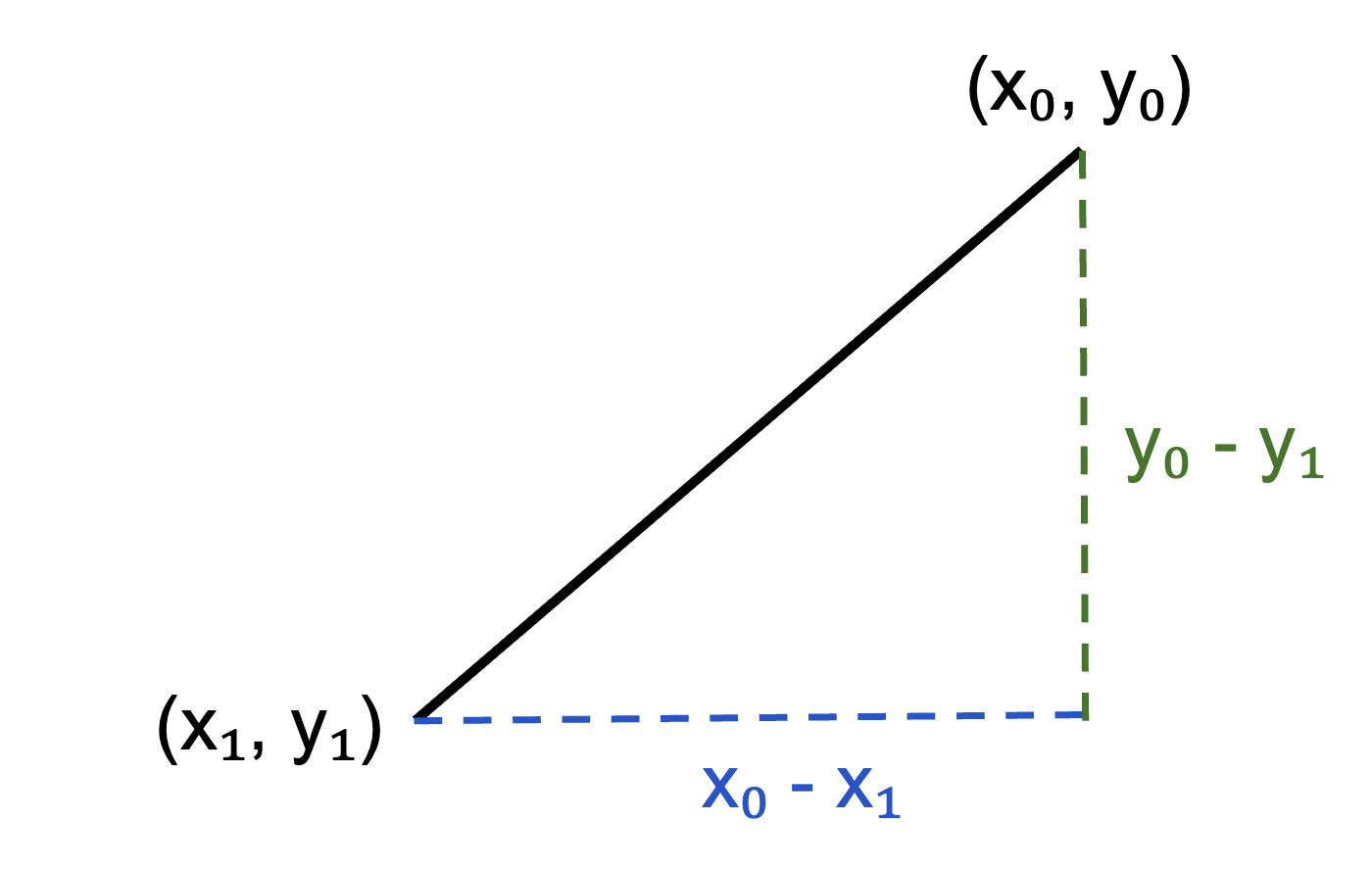
\[ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2}. \]
Two attributes x and y:
\[ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2}. \]
Three attributes x, y, z:
\[ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2 + (z_0-z_1)^2}. \]
and so on…
\[ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2}. \]
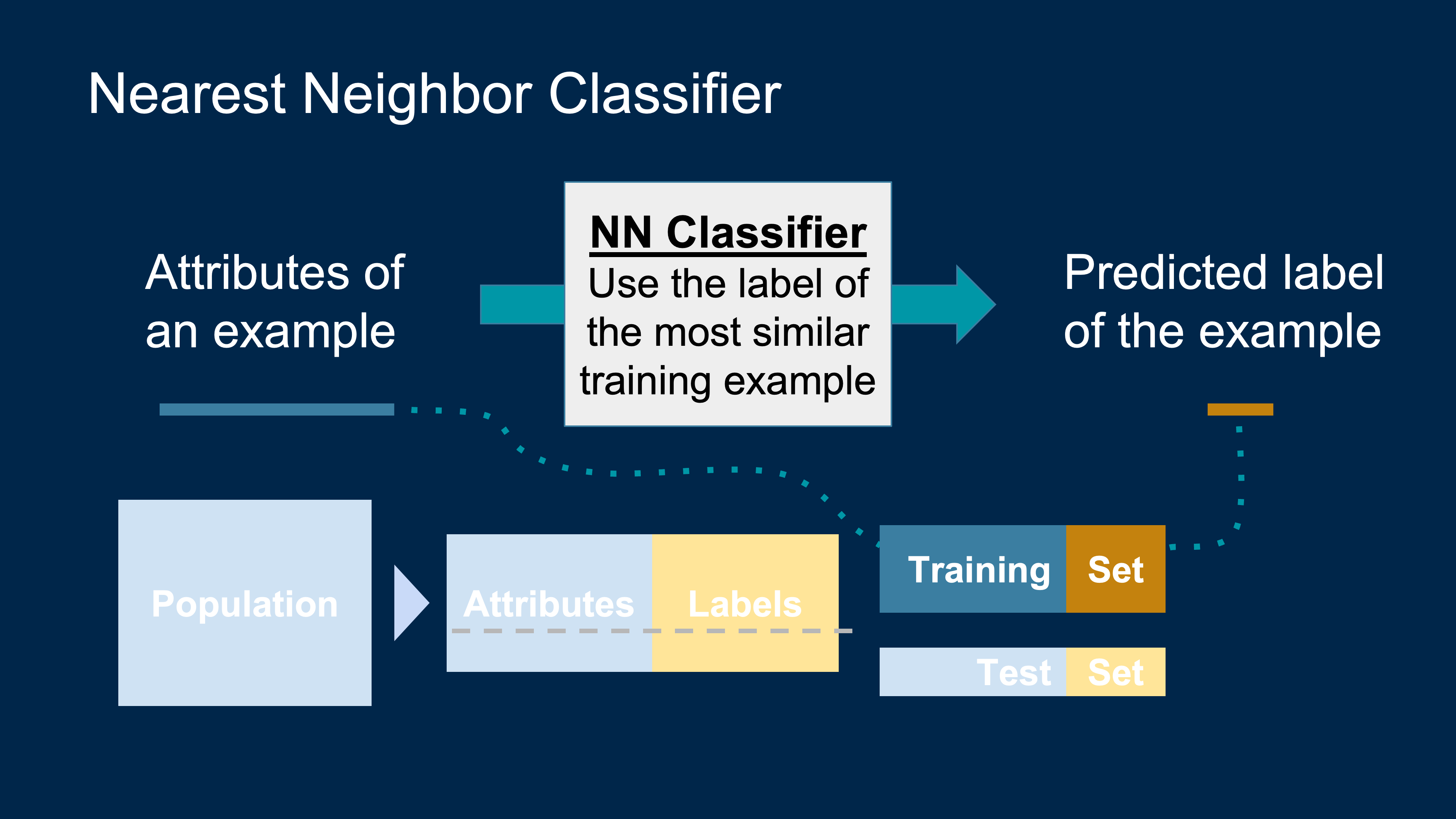
To find the k nearest neighbors of an example:
To classify a point:
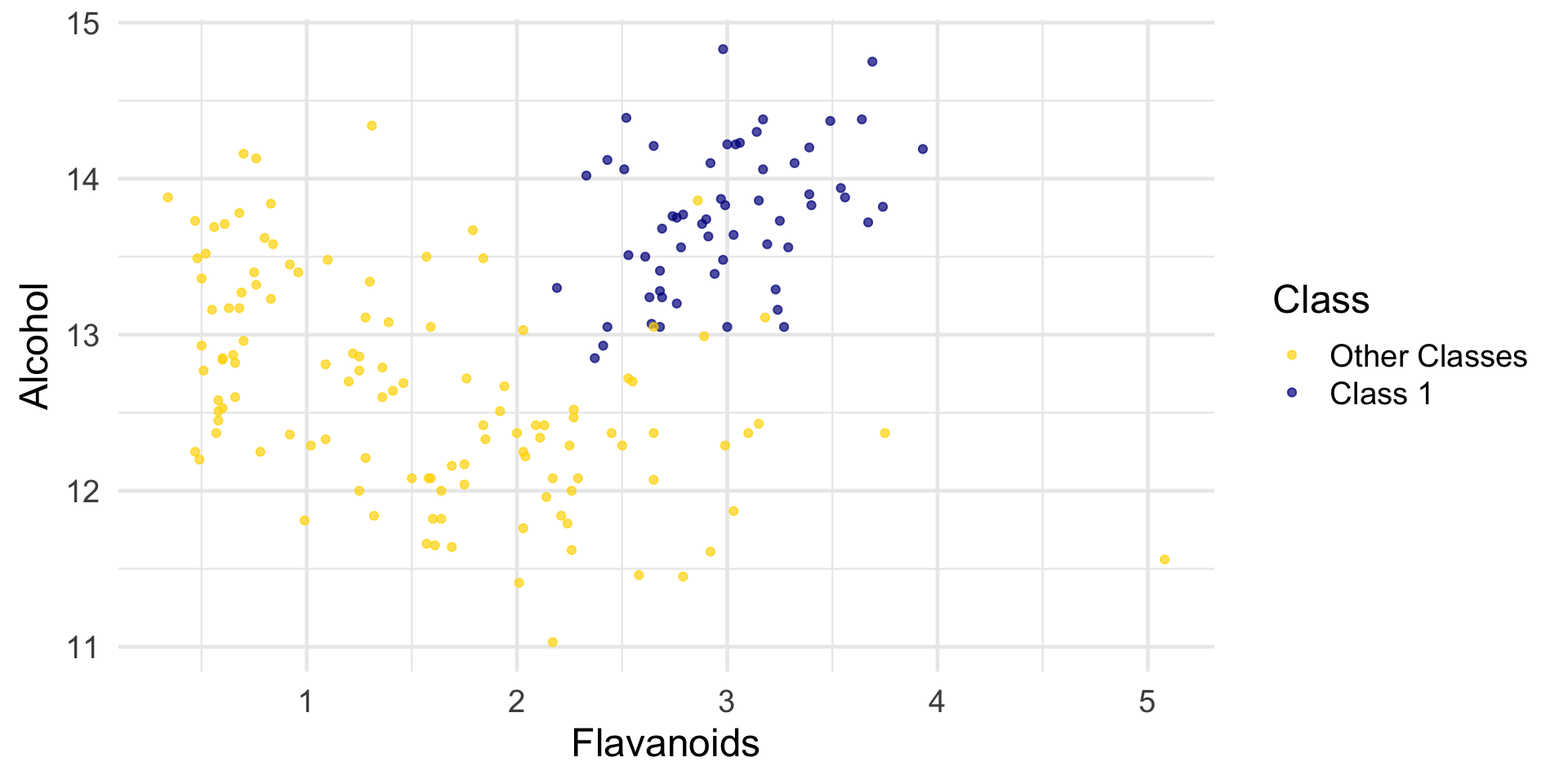
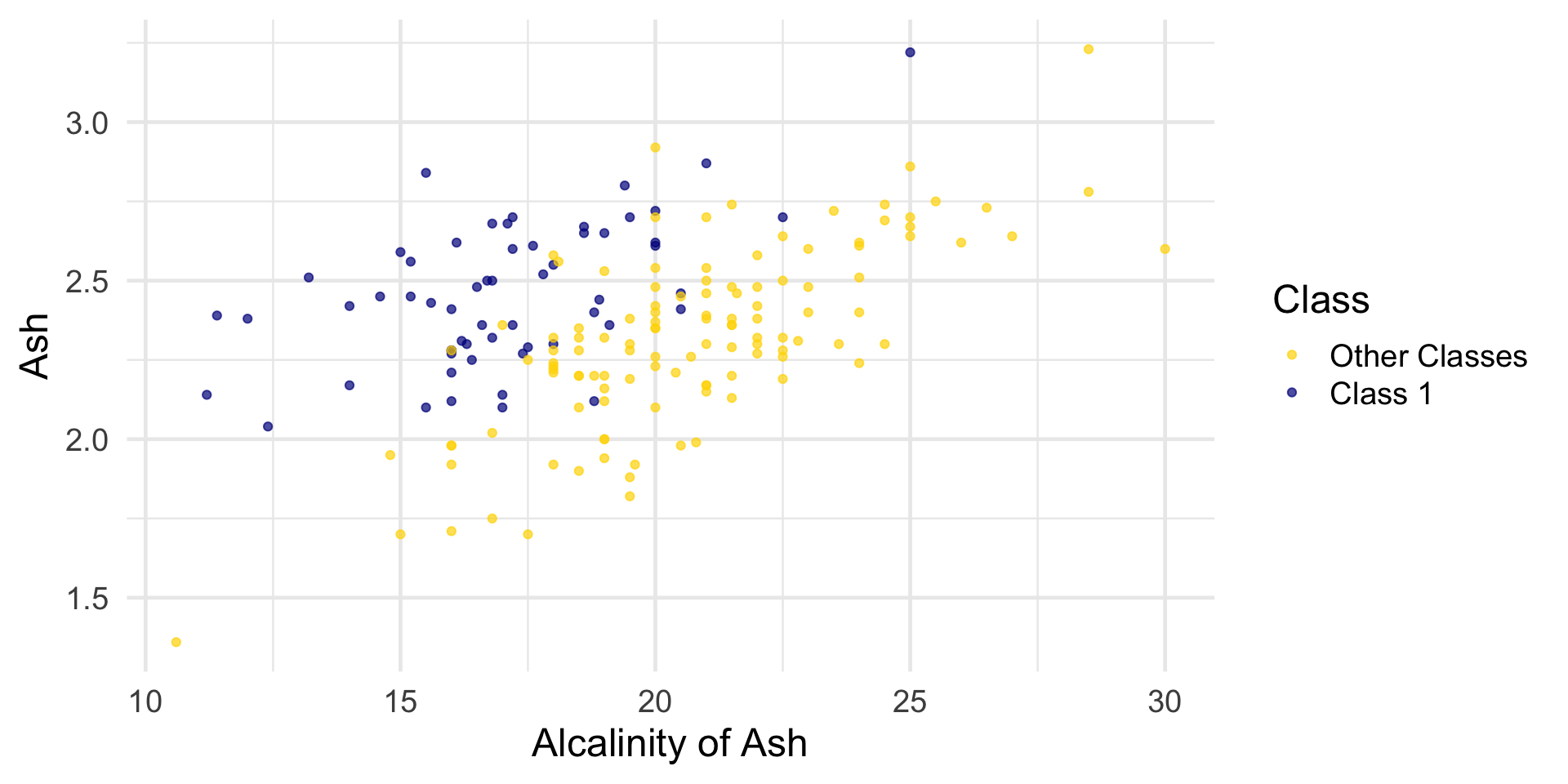
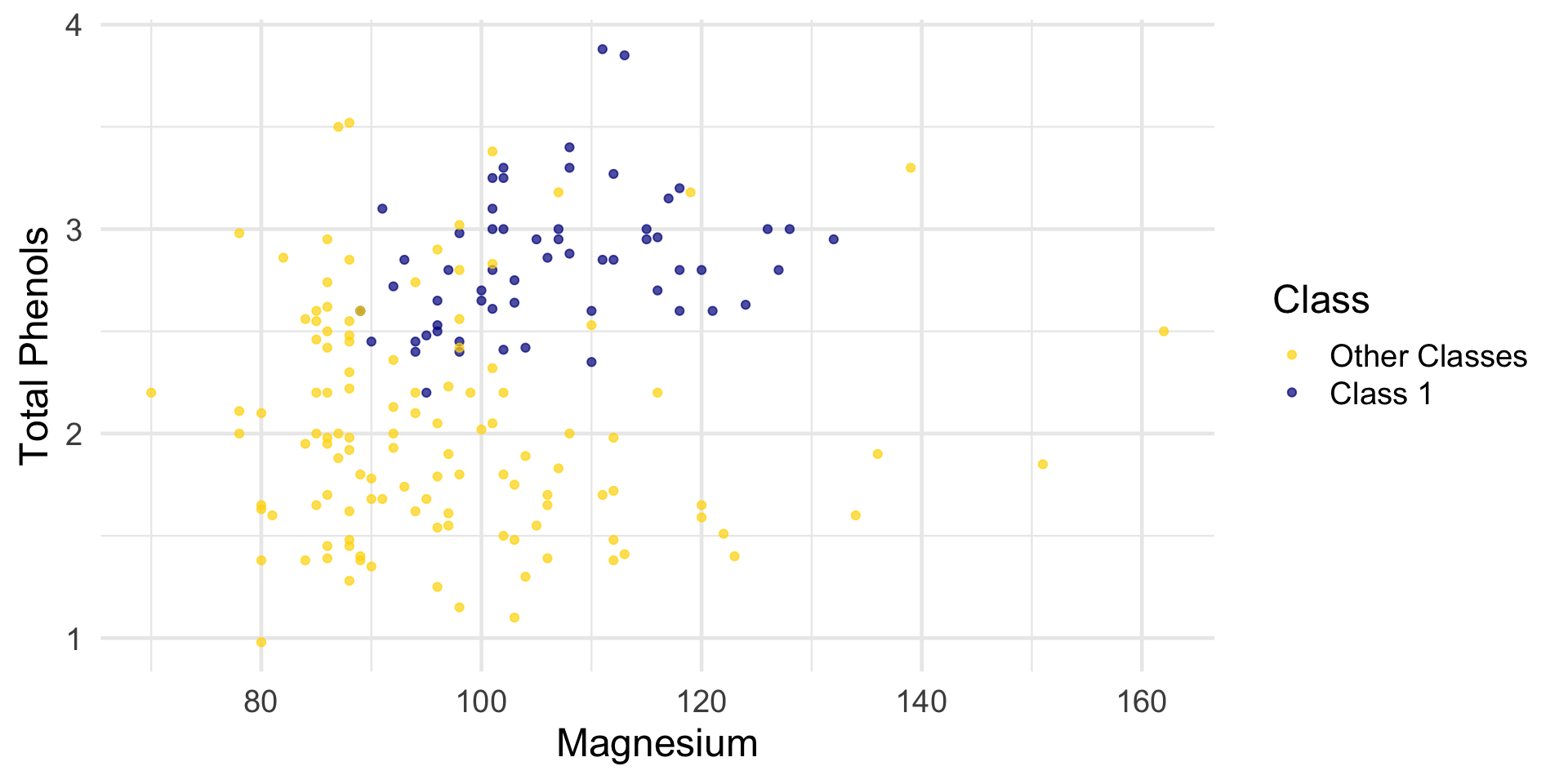
Read wine with three class. Classify Class 1 as level 1 and the other two classes as level 0.
wine <- read_csv("data/wine.csv") |>
mutate(
Class = factor(
if_else(Class == 1, 1, 0),
levels = c(0, 1),
labels = c("Other Classes", "Class 1")
)
)
wine# A tibble: 178 × 14
Class Alcohol `Malic Acid` Ash `Alcalinity of Ash` Magnesium
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Class 1 14.2 1.71 2.43 15.6 127
2 Class 1 13.2 1.78 2.14 11.2 100
3 Class 1 13.2 2.36 2.67 18.6 101
4 Class 1 14.4 1.95 2.5 16.8 113
5 Class 1 13.2 2.59 2.87 21 118
6 Class 1 14.2 1.76 2.45 15.2 112
7 Class 1 14.4 1.87 2.45 14.6 96
8 Class 1 14.1 2.15 2.61 17.6 121
9 Class 1 14.8 1.64 2.17 14 97
10 Class 1 13.9 1.35 2.27 16 98
# ℹ 168 more rows
# ℹ 8 more variables: `Total Phenols` <dbl>, Flavanoids <dbl>,
# `Nonflavanoid phenols` <dbl>, Proanthocyanins <dbl>,
# `Color Intensity` <dbl>, Hue <dbl>, `OD280/OD315 of diulted wines` <dbl>,
# Proline <dbl>The first two wines are both in Class 1. To find the distance between them, we first need a data frame of just the attributes:
[1] 31.26501[1] 506.0594That distance is quite a bit bigger!
Let’s see if we can implement a classifier based on all of the attributes.
The general approach is:
point.point.We’ll use the tidymodels framework to implement the classifier.
Set up the model specification.
kknn engine (an implementation of k-NN)."classification" because we want to predict a class label.Next, we define how the model should learn from the data.
Now we can plug in a row of predictor values to make a prediction:
What about something from Other Classes?
# A tibble: 1 × 1
.pred_class
<fct>
1 Other ClassesYes! The classifier gets this one right too.
But we don’t yet know how it does with all the other wines. Also, testing on wines that are already part of the training set might be over-optimistic.
To get an unbiased estimate of our classifier’s accuracy, we split the data into:
This is sometimes called the hold-out method.
We’ll randomly split the 178 wines into 89 training and 89 test examples.
First, we set up and train the classifier on train_data:
Then we get predictions on the test set:
The last step is to compare how many of these predictions are correct by looking at the true labels from test_data:
test_data |>
mutate(predicted = knn_preds$.pred_class) |>
accuracy(truth = Class, estimate = predicted)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.989The accuracy rate isn’t bad at all for a simple classifier!
The data set has 683 patients. We’ll randomly permute the dataset and put 342 in the training set and the remaining 341 in the test set.
Let’s stick with 5 nearest neighbors, and see how well our classifier does.
knn_spec <- nearest_neighbor(neighbors = 5) |>
set_engine("kknn") |>
set_mode("classification")
knn_fit <- knn_spec |>
fit(Class ~ ., data = train_data)
knn_preds <- predict(knn_fit, new_data = test_data)
head(knn_preds)# A tibble: 6 × 1
.pred_class
<fct>
1 benign
2 benign
3 benign
4 malignant
5 benign
6 benign Now compare predictions to the true labels to measure accuracy:
Banknotes Demo
standard_units <- function(x){
(x - mean(x))/sd(x)
}
ckd <- read_csv('data/ckd.csv') |>
rename(Glucose = `Blood Glucose Random`) |>
mutate(
Hemoglobin = standard_units(Hemoglobin),
Glucose = standard_units(Glucose),
`White Blood Cell Count` = standard_units(`White Blood Cell Count`),
Class = factor(Class,
levels = c(0, 1),
labels = c("No CKD", "CKD"))
) |>
select(Hemoglobin, Glucose, `White Blood Cell Count`, Class)data_split <- initial_split(patients, prop = 75/148, strata = Class)
train_data <- training(data_split)
test_data <- testing(data_split)
knn_spec <- nearest_neighbor(neighbors = 5) |>
set_engine("kknn") |>
set_mode("classification")
knn_fit <- knn_spec |>
fit(Class ~ ., data = train_data)
knn_preds <- predict(knn_fit, new_data = test_data)
test_data |>
mutate(predicted = knn_preds$.pred_class) |>
accuracy(truth = Class, estimate = predicted)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.979