library(tidyverse) # let's load in everything
set.seed(7) # we are going to create something random
# the 'seed' is so my random looks like your random
N <- 60 #number of observations
lifelog <- tibble(
id = 1:N, # identifier (categorical by meaning)
age = sample(18:35, N, replace = TRUE), # numeric (discrete integer)
height_cm = round(rnorm(N, mean = 170, sd = 10), 1), # continuous
commute_mode = sample(c("Walk","Bike","Transit","Car"), N, replace = TRUE), # categorical (nominal)
coffee_cups = sample(0:5, N, replace = TRUE), # counts (discrete numeric)
coffee_today = coffee_cups > 0, # logical/binary (categorical by meaning)
study_hours = round(runif(N, 0, 6), 1), # continuous
mood = factor(sample(c("Low","Medium","High"), N, replace = TRUE),
levels = c("Low","Medium","High"), ordered = TRUE), # categorical (ordinal)
zip_code = sample(c("20001","20002","20037","20052"), N, replace = TRUE) # numeric-looking categorical
)Categorical vs. Continuous Data
Sarah Cassie Burnett
October 7, 2025
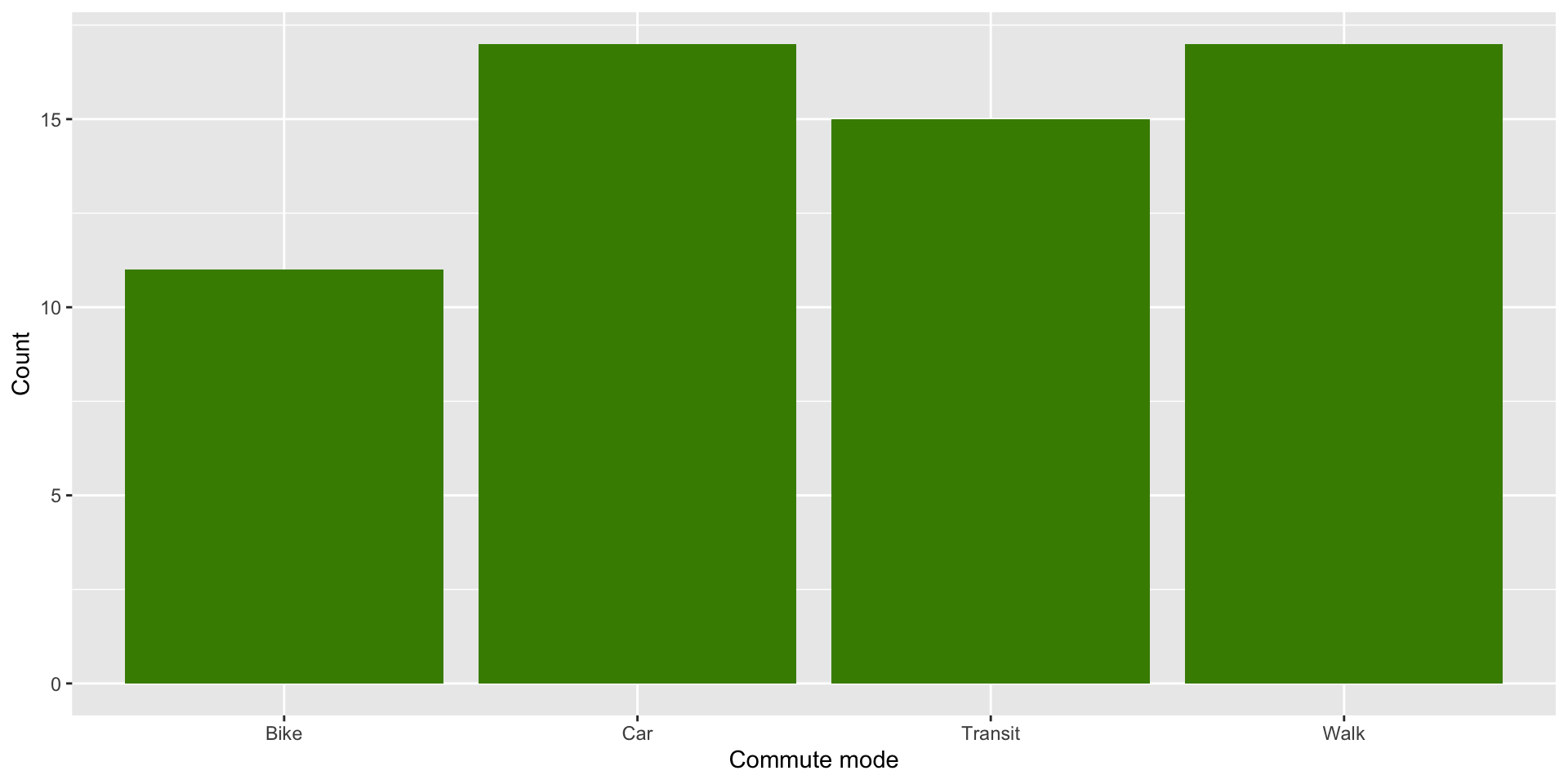
Visualize
Single categorical variable: use bar chart
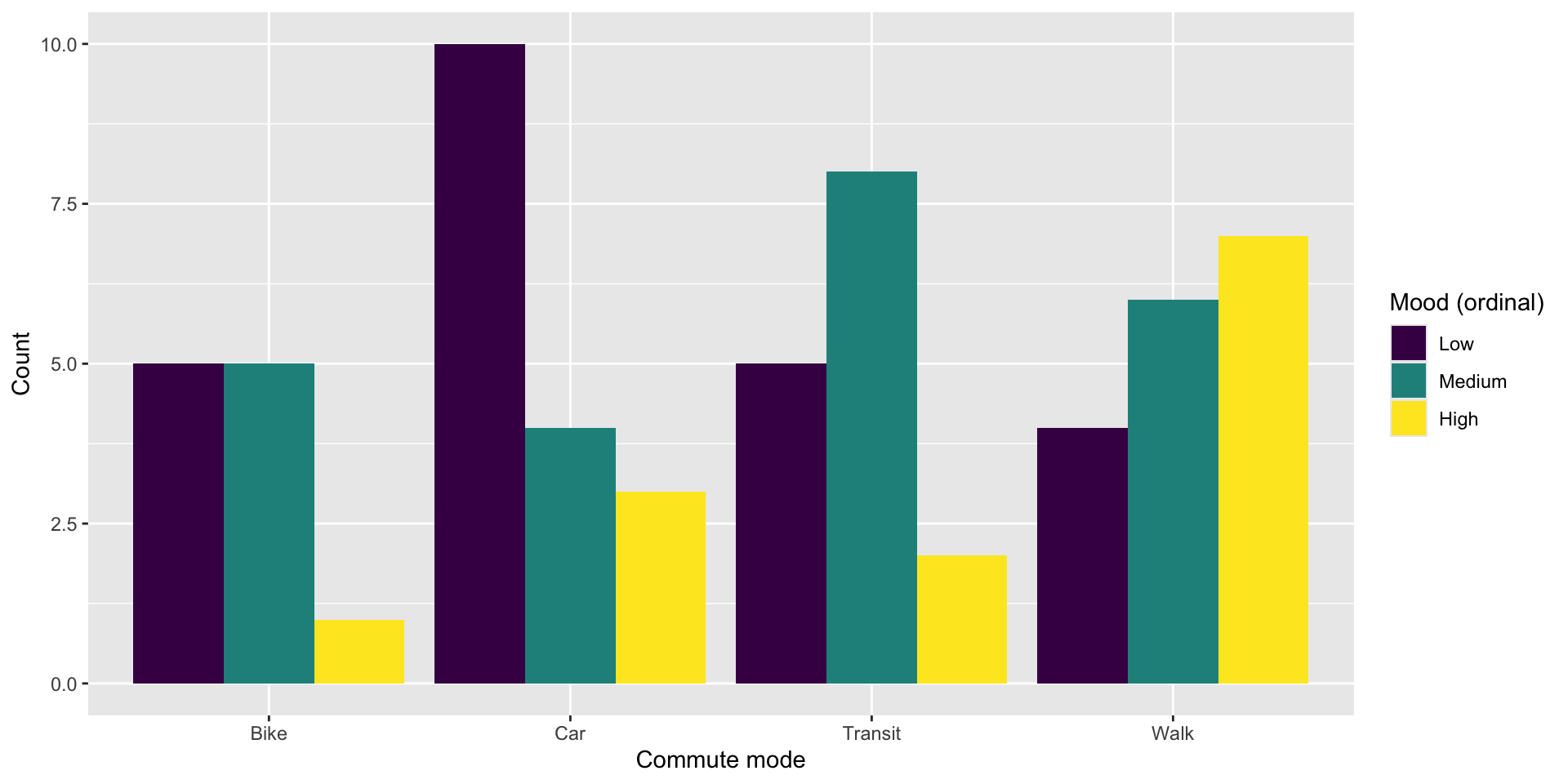
Visualize
Two categorical variables: dodged bars
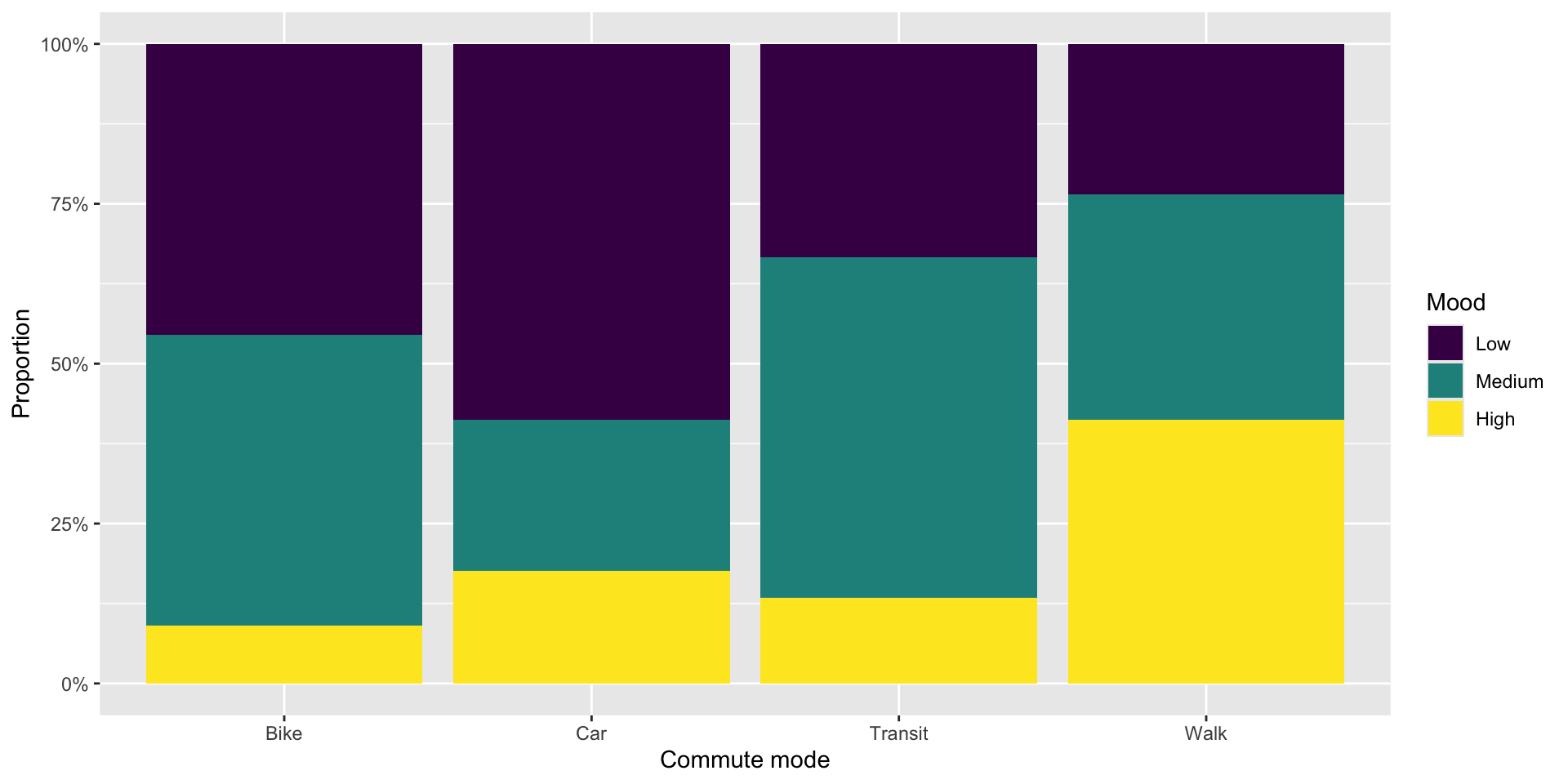
Visualize
Two categorical variables: stacked bars
Visualize
One continuous variable: histogram
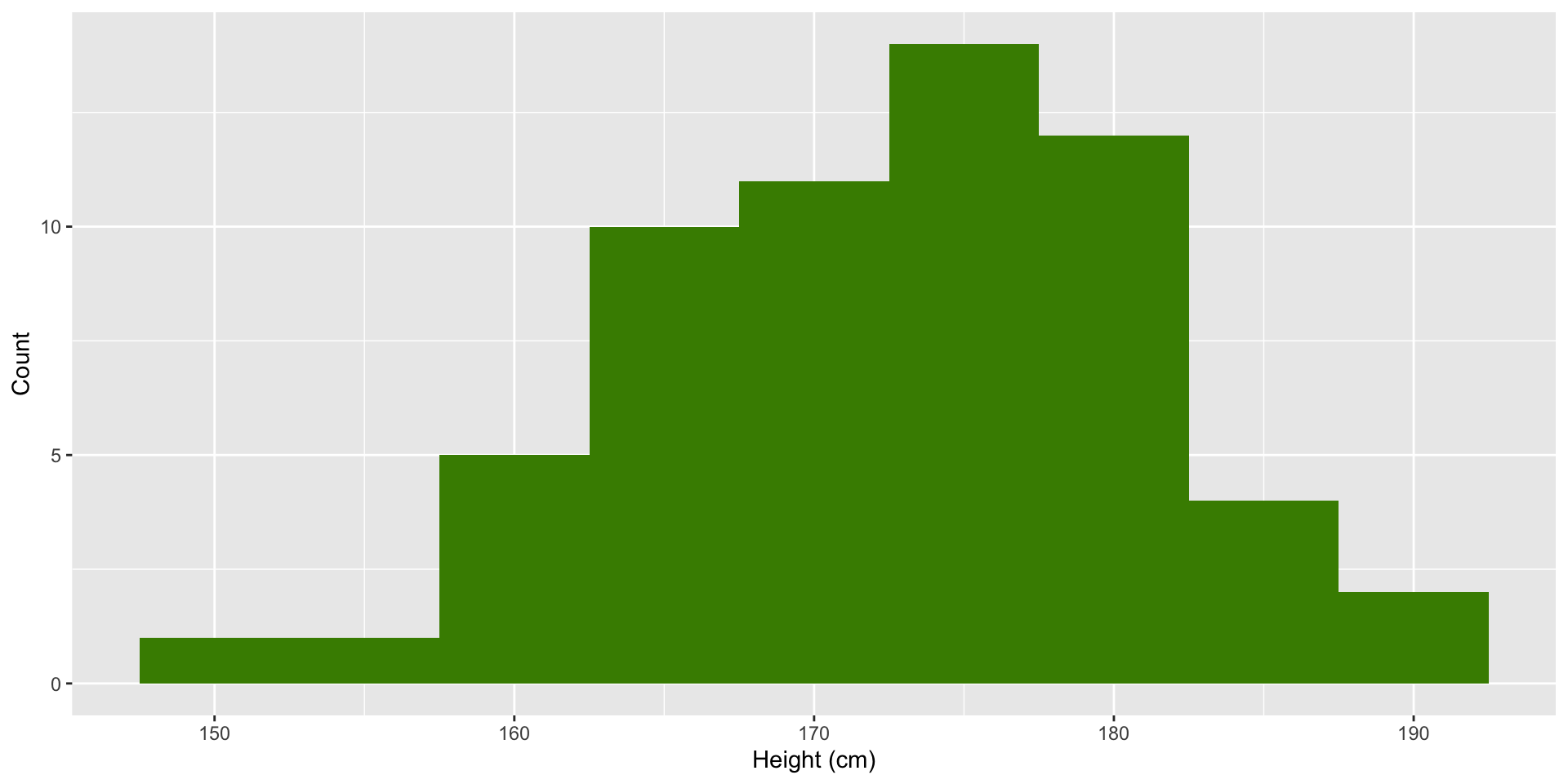
Visualize
Two continuous variables: scatterplots
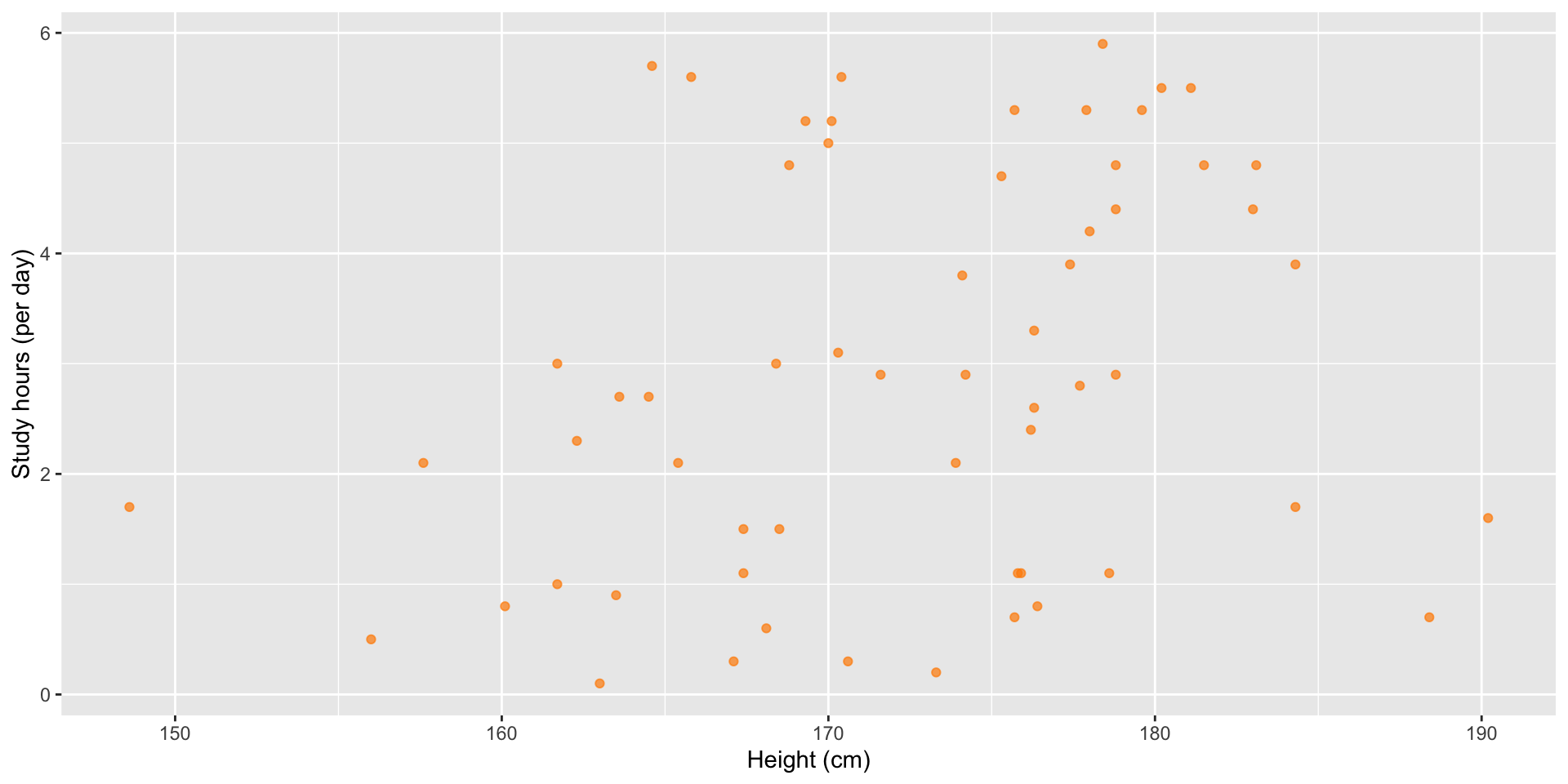
If one variable was time, a line chart would be recommended here.
Visualize
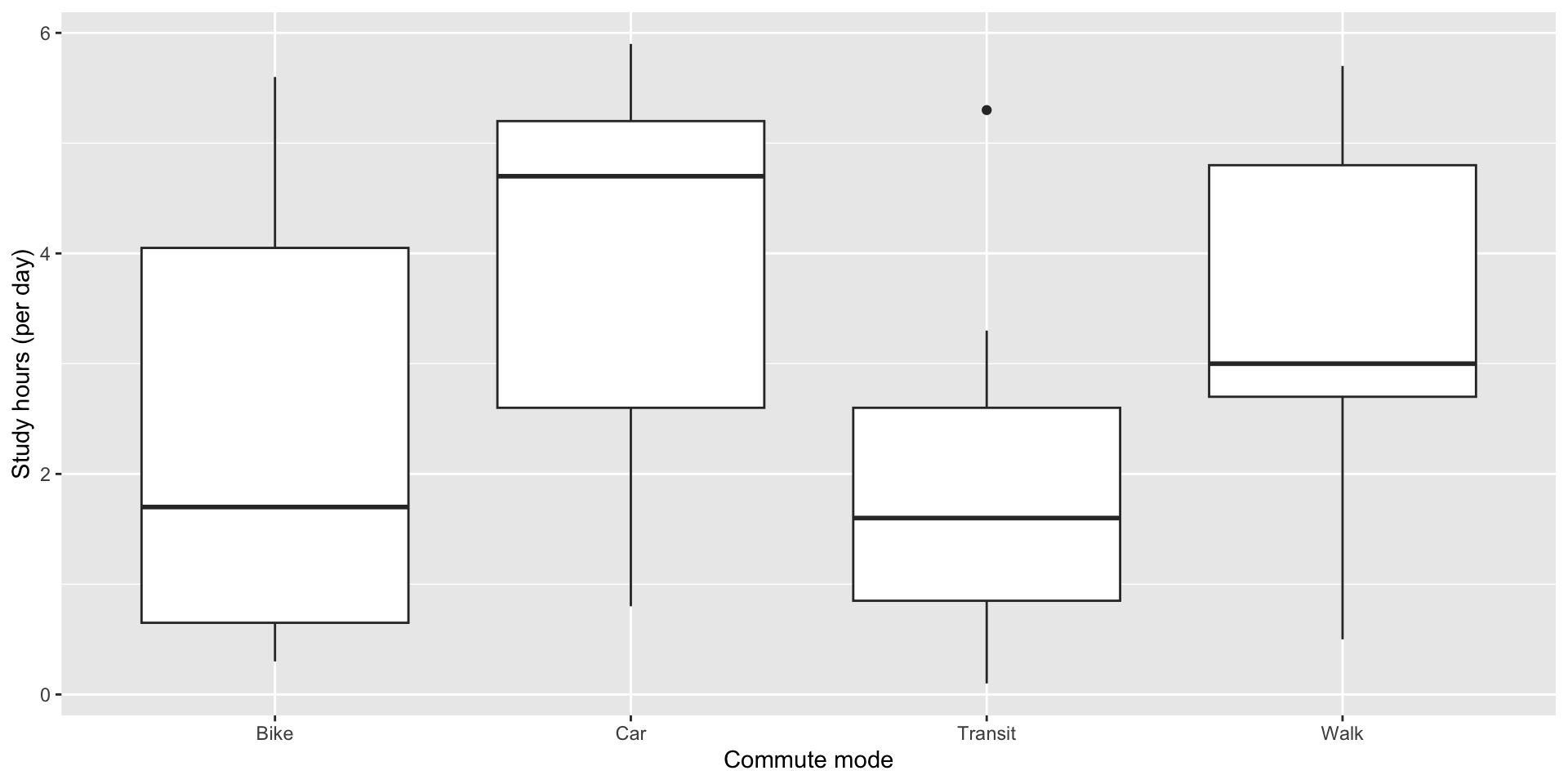
Histogram of continuous variable by category (not easy to see)
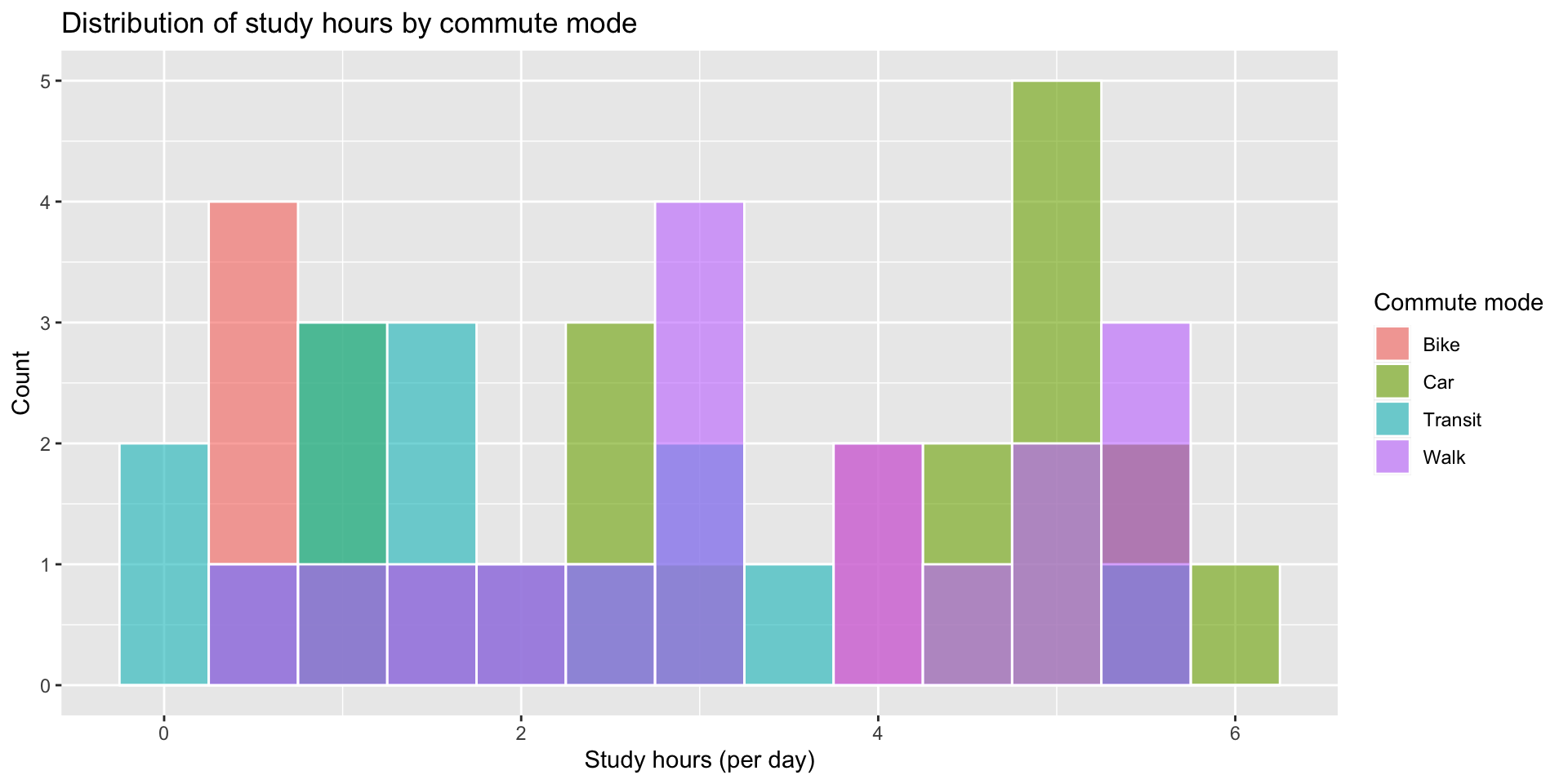
Visualize
Boxplot of continuous by categorical