Classification
This module was adapted from the chapter in the Data 8 textbook.
1 Classification
David Wagner is the primary author of this chapter.
Machine learning is a class of techniques for automatically finding patterns in data and using it to draw inferences or make predictions. You have already seen linear regression, which is one kind of machine learning. This chapter introduces a new one: classification.
Classification is about learning how to make predictions from past examples. We are given some examples where we have been told what the correct prediction was, and we want to learn from those examples how to make good predictions in the future. Here are a few applications where classification is used in practice:
For each order Amazon receives, Amazon would like to predict: is this order fraudulent? They have some information about each order (e.g., its total value, whether the order is being shipped to an address this customer has used before, whether the shipping address is the same as the credit card holder’s billing address). They have lots of data on past orders, and they know which of those past orders were fraudulent and which weren’t. They want to learn patterns that will help them predict, as new orders arrive, whether those new orders are fraudulent.
Online dating sites would like to predict: are these two people compatible? Will they hit it off? They have lots of data on which matches they’ve suggested to their customers in the past, and they have some idea which ones were successful. As new customers sign up, they’d like to make predictions about who might be a good match for them.
Doctors would like to know: does this patient have cancer? Based on the measurements from some lab test, they’d like to be able to predict whether the particular patient has cancer. They have lots of data on past patients, including their lab measurements and whether they ultimately developed cancer, and from that, they’d like to try to infer what measurements tend to be characteristic of cancer (or non-cancer) so they can diagnose future patients accurately.
Politicians would like to predict: are you going to vote for them? This will help them focus fundraising efforts on people who are likely to support them, and focus get-out-the-vote efforts on voters who will vote for them. Public databases and commercial databases have a lot of information about most people: e.g., whether they own a home or rent; whether they live in a rich neighborhood or poor neighborhood; their interests and hobbies; their shopping habits; and so on. And political campaigns have surveyed some voters and found out who they plan to vote for, so they have some examples where the correct answer is known. From this data, the campaigns would like to find patterns that will help them make predictions about all other potential voters.
All of these are classification tasks. Notice that in each of these examples, the prediction is a yes/no question – we call this binary classification, because there are only two possible predictions.
In a classification task, each individual or situation where we’d like to make a prediction is called an observation. We ordinarily have many observations. Each observation has multiple attributes, which are known (for example, the total value of the order on Amazon, or the voter’s annual salary). Also, each observation has a class, which is the answer to the question we care about (for example, fraudulent or not, or voting for you or not).
When Amazon is predicting whether orders are fraudulent, each order corresponds to a single observation. Each observation has several attributes: the total value of the order, whether the order is being shipped to an address this customer has used before, and so on. The class of the observation is either 0 or 1, where 0 means that the order is not fraudulent and 1 means that the order is fraudulent. When a customer makes a new order, we do not observe whether it is fraudulent, but we do observe its attributes, and we will try to predict its class using those attributes.
Classification requires data. It involves looking for patterns, and to find patterns, you need data. That’s where the data science comes in. In particular, we’re going to assume that we have access to training data: a bunch of observations, where we know the class of each observation. The collection of these pre-classified observations is also called a training set. A classification algorithm is going to analyze the training set, and then come up with a classifier: an algorithm for predicting the class of future observations.
Classifiers do not need to be perfect to be useful. They can be useful even if their accuracy is less than 100%. For instance, if the online dating site occasionally makes a bad recommendation, that’s OK; their customers already expect to have to meet many people before they’ll find someone they hit it off with. Of course, you don’t want the classifier to make too many errors — but it doesn’t have to get the right answer every single time.
1.1 Nearest Neighbors
In this section we’ll develop the nearest neighbor method of classification. Just focus on the ideas for now and don’t worry if some of the code is mysterious. Later in the chapter we’ll see how to organize our ideas into code that performs the classification.
1.1.1 Chronic kidney disease
Let’s work through an example. We’re going to work with a data set that was collected to help doctors diagnose chronic kidney disease (CKD). You can find ckd.csv under Resources on Blackboard. Each row in the data set represents a single patient who was treated in the past and whose diagnosis is known. For each patient, we have a bunch of measurements from a blood test. We’d like to find which measurements are most useful for diagnosing CKD, and develop a way to classify future patients as “has CKD” or “doesn’t have CKD” based on their blood test results.
ckd| Age | Blood Pressure | Specific Gravity | Albumin | Sugar | Red Blood Cells | Pus Cell | Pus Cell clumps | Bacteria | Glucose | Blood Urea | Serum Creatinine | Sodium | Potassium | Hemoglobin | Packed Cell Volume | White Blood Cell Count | Red Blood Cell Count | Hypertension | Diabetes Mellitus | Coronary Artery Disease | Appetite | Pedal Edema | Anemia | Class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 48 | 70 | 1.005 | 4 | 0 | normal | abnormal | present | notpresent | 117 | 56 | 3.8 | 111 | 2.5 | 11.2 | 32 | 6700 | 3.9 | yes | no | no | poor | yes | yes | 1 |
| 53 | 90 | 1.020 | 2 | 0 | abnormal | abnormal | present | notpresent | 70 | 107 | 7.2 | 114 | 3.7 | 9.5 | 29 | 12100 | 3.7 | yes | yes | no | poor | no | yes | 1 |
| 63 | 70 | 1.010 | 3 | 0 | abnormal | abnormal | present | notpresent | 380 | 60 | 2.7 | 131 | 4.2 | 10.8 | 32 | 4500 | 3.8 | yes | yes | no | poor | yes | no | 1 |
| 68 | 80 | 1.010 | 3 | 2 | normal | abnormal | present | present | 157 | 90 | 4.1 | 130 | 6.4 | 5.6 | 16 | 11000 | 2.6 | yes | yes | yes | poor | yes | no | 1 |
| 61 | 80 | 1.015 | 2 | 0 | abnormal | abnormal | notpresent | notpresent | 173 | 148 | 3.9 | 135 | 5.2 | 7.7 | 24 | 9200 | 3.2 | yes | yes | yes | poor | yes | yes | 1 |
| 48 | 80 | 1.025 | 4 | 0 | normal | abnormal | notpresent | notpresent | 95 | 163 | 7.7 | 136 | 3.8 | 9.8 | 32 | 6900 | 3.4 | yes | no | no | good | no | yes | 1 |
| 69 | 70 | 1.010 | 3 | 4 | normal | abnormal | notpresent | notpresent | 264 | 87 | 2.7 | 130 | 4.0 | 12.5 | 37 | 9600 | 4.1 | yes | yes | yes | good | yes | no | 1 |
| 73 | 70 | 1.005 | 0 | 0 | normal | normal | notpresent | notpresent | 70 | 32 | 0.9 | 125 | 4.0 | 10.0 | 29 | 18900 | 3.5 | yes | yes | no | good | yes | no | 1 |
| 73 | 80 | 1.020 | 2 | 0 | abnormal | abnormal | notpresent | notpresent | 253 | 142 | 4.6 | 138 | 5.8 | 10.5 | 33 | 7200 | 4.3 | yes | yes | yes | good | no | no | 1 |
| 46 | 60 | 1.010 | 1 | 0 | normal | normal | notpresent | notpresent | 163 | 92 | 3.3 | 141 | 4.0 | 9.8 | 28 | 14600 | 3.2 | yes | yes | no | good | no | no | 1 |
Showing 10 of 158 rowsSome of the variables are categorical (words like “abnormal”), and some quantitative. The quantitative variables all have different scales. We’re going to want to make comparisons and estimate distances, often by eye, so let’s select just a few of the variables and work in standard units. Then we won’t have to worry about the scale of each of the different variables.
standard_units <- function(x) {
(x - mean(x)) / sd(x)
}
ckd <- ckd |>
mutate(
Hemoglobin = standard_units(Hemoglobin),
Glucose = standard_units(Glucose),
`White Blood Cell Count` = standard_units(`White Blood Cell Count`),
Class = factor(Class,
levels = c(0, 1),
labels = c("No CKD", "CKD"))
) |>
select(Hemoglobin, Glucose, `White Blood Cell Count`, Class)ckd| Hemoglobin | Glucose | White Blood Cell Count | Class |
|---|---|---|---|
| -0.863 | -0.221 | -0.568 | CKD |
| -1.453 | -0.945 | 1.159 | CKD |
| -1.002 | 3.829 | -1.272 | CKD |
| -2.806 | 0.395 | 0.807 | CKD |
| -2.077 | 0.641 | 0.232 | CKD |
| -1.349 | -0.560 | -0.504 | CKD |
| -0.412 | 2.043 | 0.359 | CKD |
| -1.279 | -0.945 | 3.334 | CKD |
| -1.106 | 1.873 | -0.408 | CKD |
| -1.349 | 0.488 | 1.959 | CKD |
Showing 10 of 158 rowsLet’s look at two columns in particular: the hemoglobin level (in the patient’s blood), and the blood glucose level (at a random time in the day; without fasting specially for the blood test).
We’ll draw a scatter plot to visualize the relation between the two variables. Blue dots are patients with CKD; gold dots are patients without CKD. What kind of medical test results seem to indicate CKD?
library(ggplot2)
ggplot(ckd, aes(x = Hemoglobin, y = Glucose, color = Class)) +
geom_point() +
scale_color_manual(
values = c("No CKD" = "gold", "CKD" = "darkblue")
) +
theme_minimal()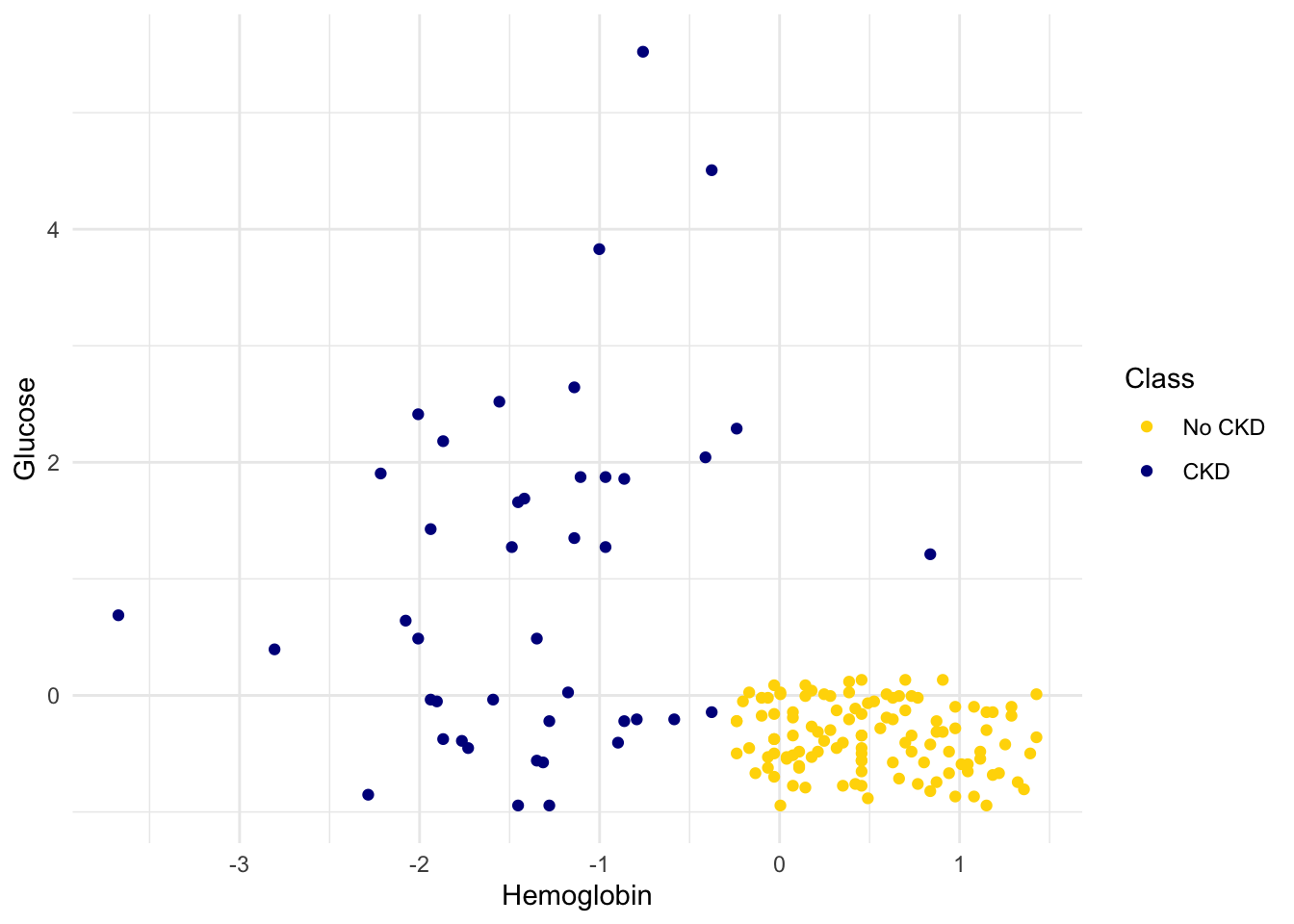
Suppose Alice is a new patient who is not in the data set. If I tell you Alice’s hemoglobin level and blood glucose level, could you predict whether she has CKD? It sure looks like it! You can see a very clear pattern here: points in the lower-right tend to represent people who don’t have CKD, and the rest tend to be folks with CKD. To a human, the pattern is obvious. But how can we program a computer to automatically detect patterns such as this one?
1.1.2 A Nearest Neighbor Classifier
There are lots of kinds of patterns one might look for, and lots of algorithms for classification. But I’m going to tell you about one that turns out to be surprisingly effective. It is called nearest neighbor classification. Here’s the idea. If we have Alice’s hemoglobin and glucose numbers, we can put her somewhere on this scatterplot; the hemoglobin is her x-coordinate, and the glucose is her y-coordinate. Now, to predict whether she has CKD or not, we find the nearest point in the scatterplot and check whether it is blue or gold; we predict that Alice should receive the same diagnosis as that patient.
In other words, to classify Alice as CKD or not, we find the patient in the training set who is “nearest” to Alice, and then use that patient’s diagnosis as our prediction for Alice. The intuition is that if two points are near each other in the scatterplot, then the corresponding measurements are pretty similar, so we might expect them to receive the same diagnosis (more likely than not). We don’t know Alice’s diagnosis, but we do know the diagnosis of all the patients in the training set, so we find the patient in the training set who is most similar to Alice, and use that patient’s diagnosis to predict Alice’s diagnosis.
In the graph below, the red dot represents Alice. It is joined with a black line to the point that is nearest to it – its nearest neighbor in the training set. The figure is drawn by an original helper function called show_closest. It takes a vector that represents the \(x\) and \(y\) coordinates of Alice’s point. Vary those to see how the closest point changes! Note especially when the closest point is blue and when it is gold.
## In this example, Alice's Hemoglobin attribute is 0 and her Glucose is 1.5.
alice = c(0, 1.5)
show_closest(alice)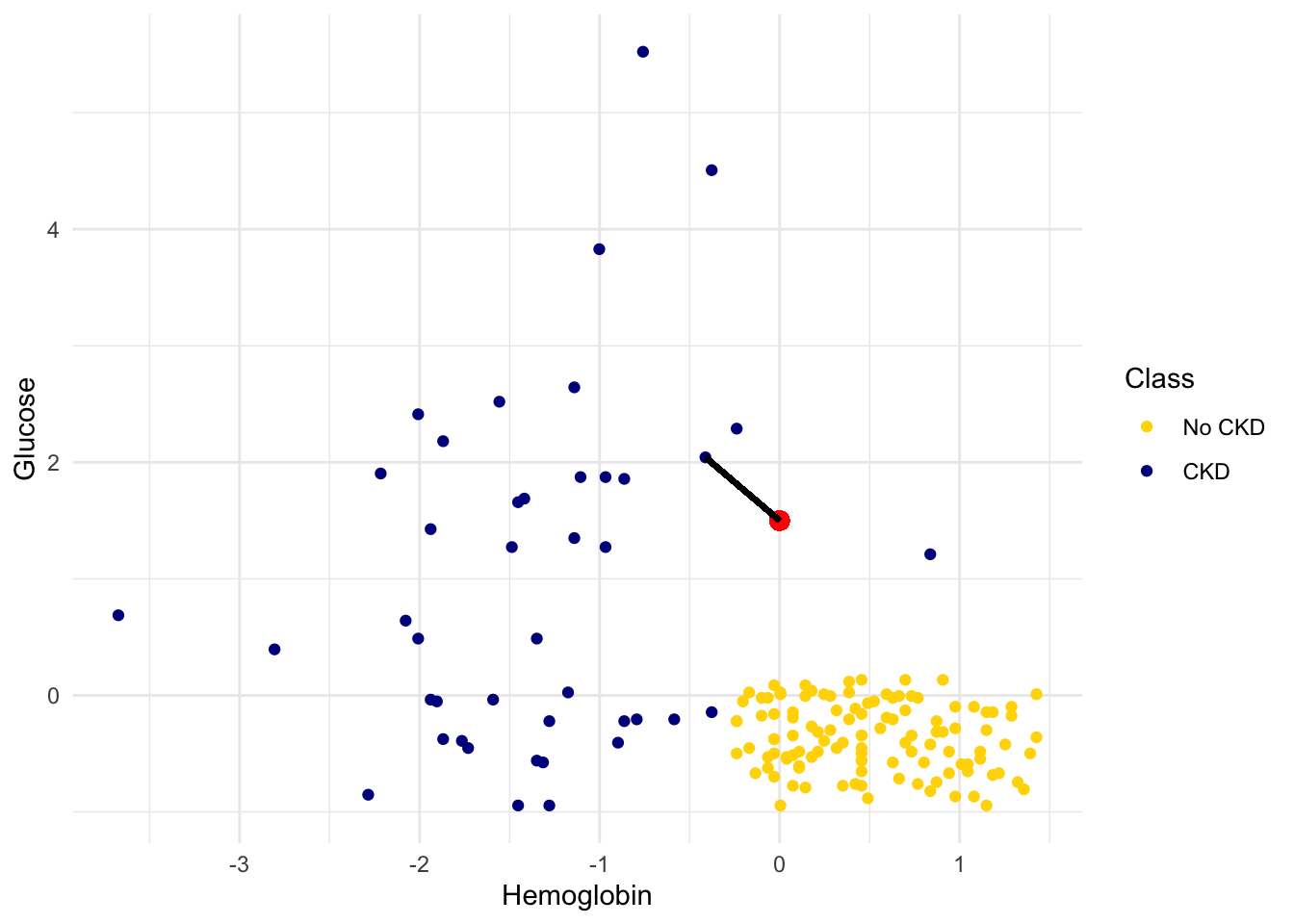
Thus our nearest neighbor classifier works like this:
- Find the point in the training set that is nearest to the new point.
- If that nearest point is a “CKD” point, classify the new point as “CKD”. If the nearest point is a “not CKD” point, classify the new point as “not CKD”.
The scatterplot suggests that this nearest neighbor classifier should be pretty accurate. Points in the lower-right will tend to receive a “no CKD” diagnosis, as their nearest neighbor will be a gold point. The rest of the points will tend to receive a “CKD” diagnosis, as their nearest neighbor will be a blue point. So the nearest neighbor strategy seems to capture our intuition pretty well, for this example.
1.1.3 Decision boundary
Sometimes a helpful way to visualize a classifier is to map out the kinds of attributes where the classifier would predict ‘CKD’, and the kinds where it would predict ‘not CKD’. We end up with some boundary between the two, where points on one side of the boundary will be classified ‘CKD’ and points on the other side will be classified ‘not CKD’. This boundary is called the decision boundary. Each different classifier will have a different decision boundary; the decision boundary is just a way to visualize what criteria the classifier is using to classify points.
For example, suppose the coordinates of Alice’s point are (0, 1.5). Notice that the nearest neighbor is blue. Now try reducing the height (the \(y\)-coordinate) of the point. You’ll see that at around \(y = 0.95\) the nearest neighbor turns from blue to gold.
alice = c(0, 0.97)
show_closest(alice)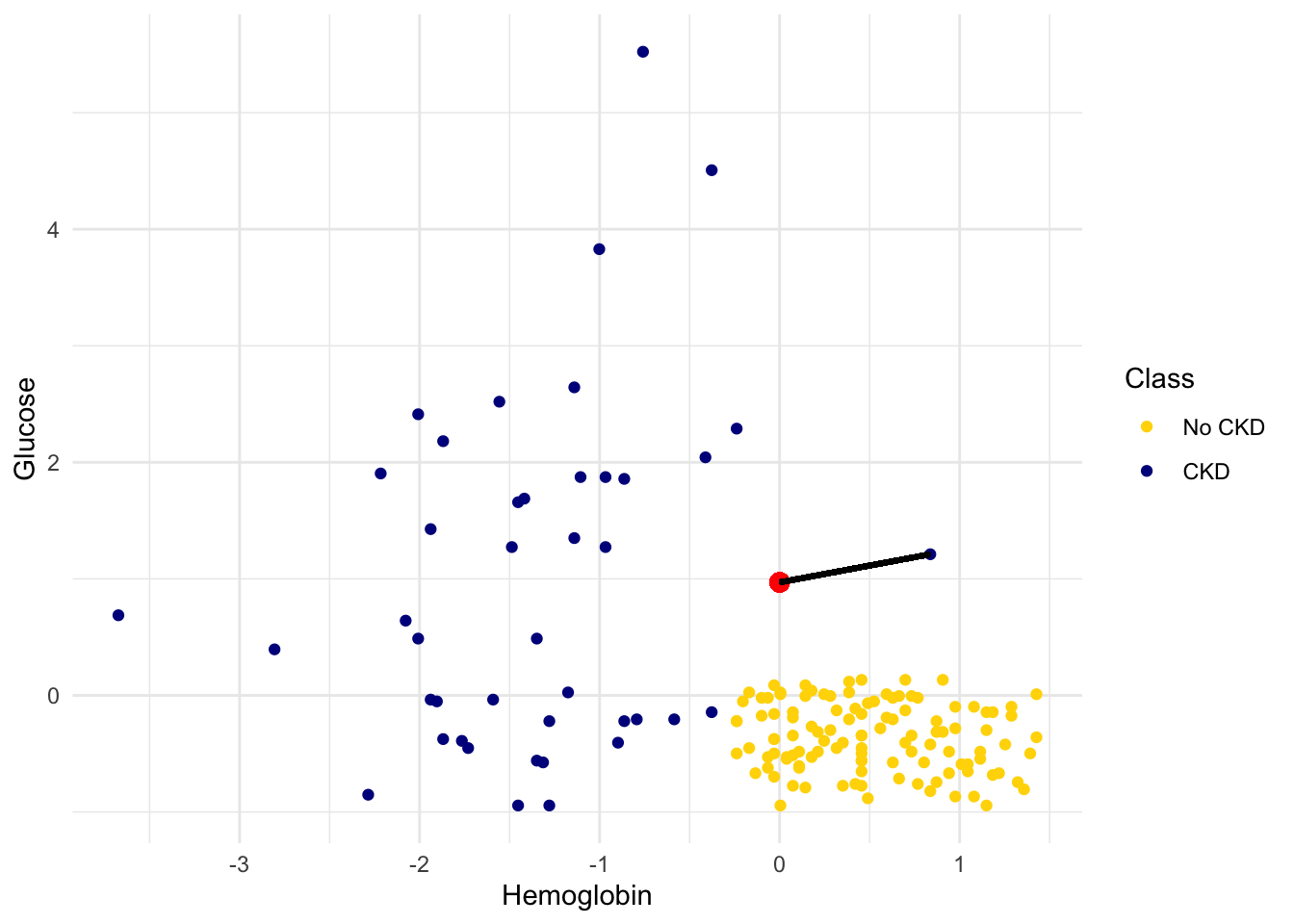
Here are hundreds of new unclassified points, all in red.
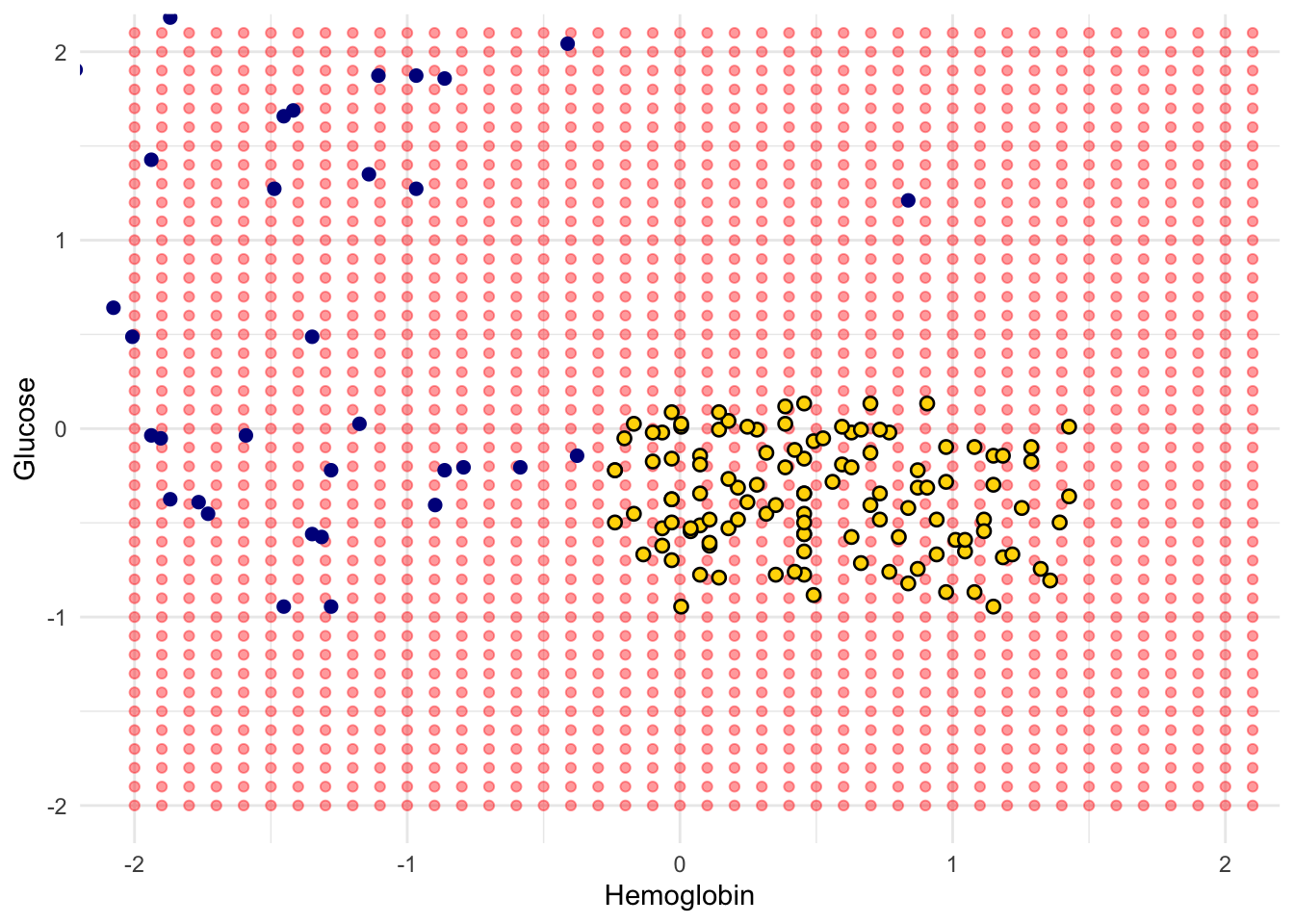
Each of the red points has a nearest neighbor in the training set (the same blue and gold points as before). For some red points you can easily tell whether the nearest neighbor is blue or gold. For others, it’s a little more tricky to make the decision by eye. Those are the points near the decision boundary.
But the computer can easily determine the nearest neighbor of each point. So let’s get it to apply our nearest neighbor classifier to each of the red points:
For each red point, it must find the closest point in the training set; it must then change the color of the red point to become the color of the nearest neighbor.
The resulting graph shows which points will get classified as ‘CKD’ (all the blue ones), and which as ‘not CKD’ (all the gold ones).
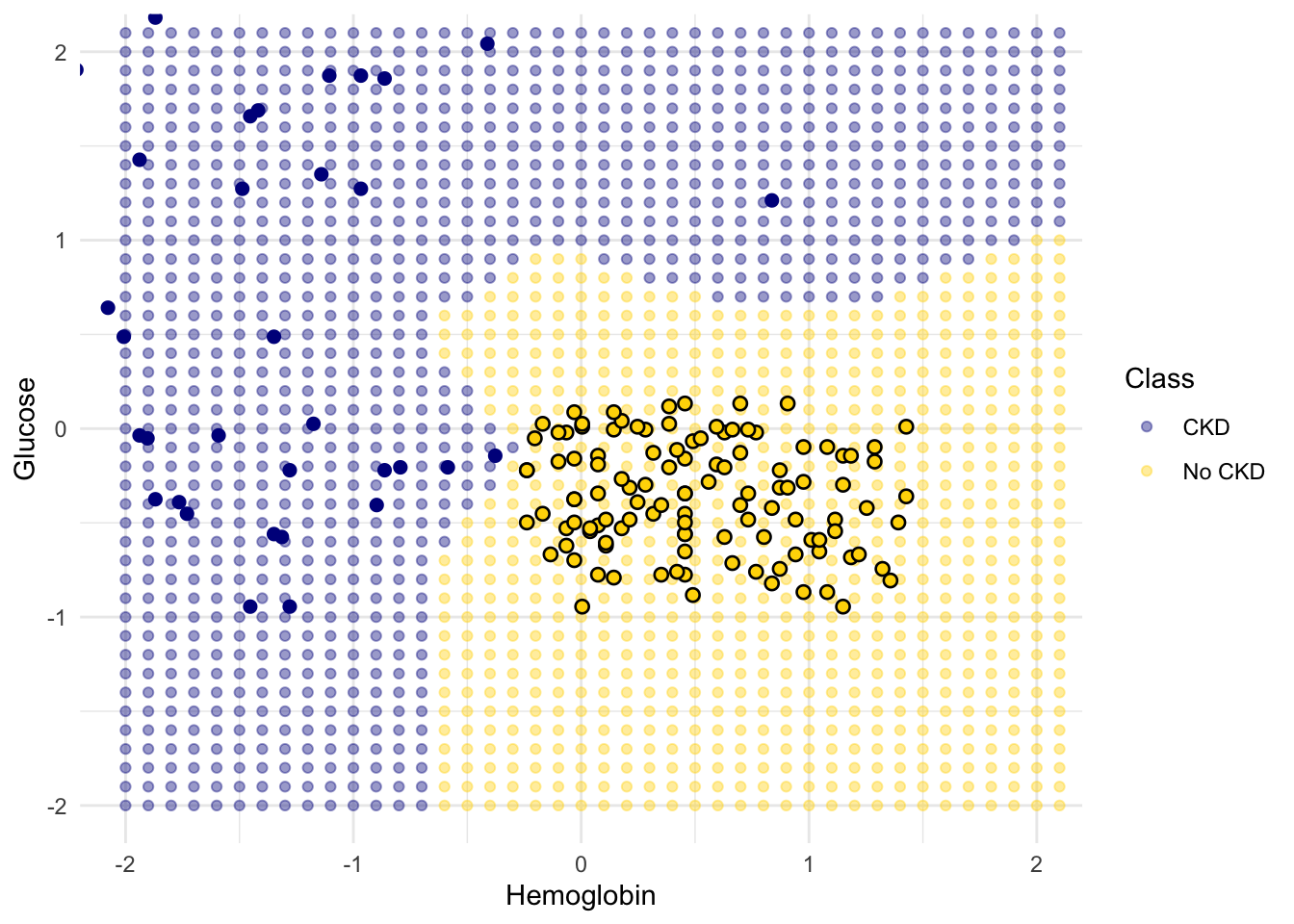
1.1.4 k-Nearest Neighbors
However, the separation between the two classes won’t always be quite so clean. For instance, suppose that instead of hemoglobin levels we were to look at white blood cell count. Look at what happens:
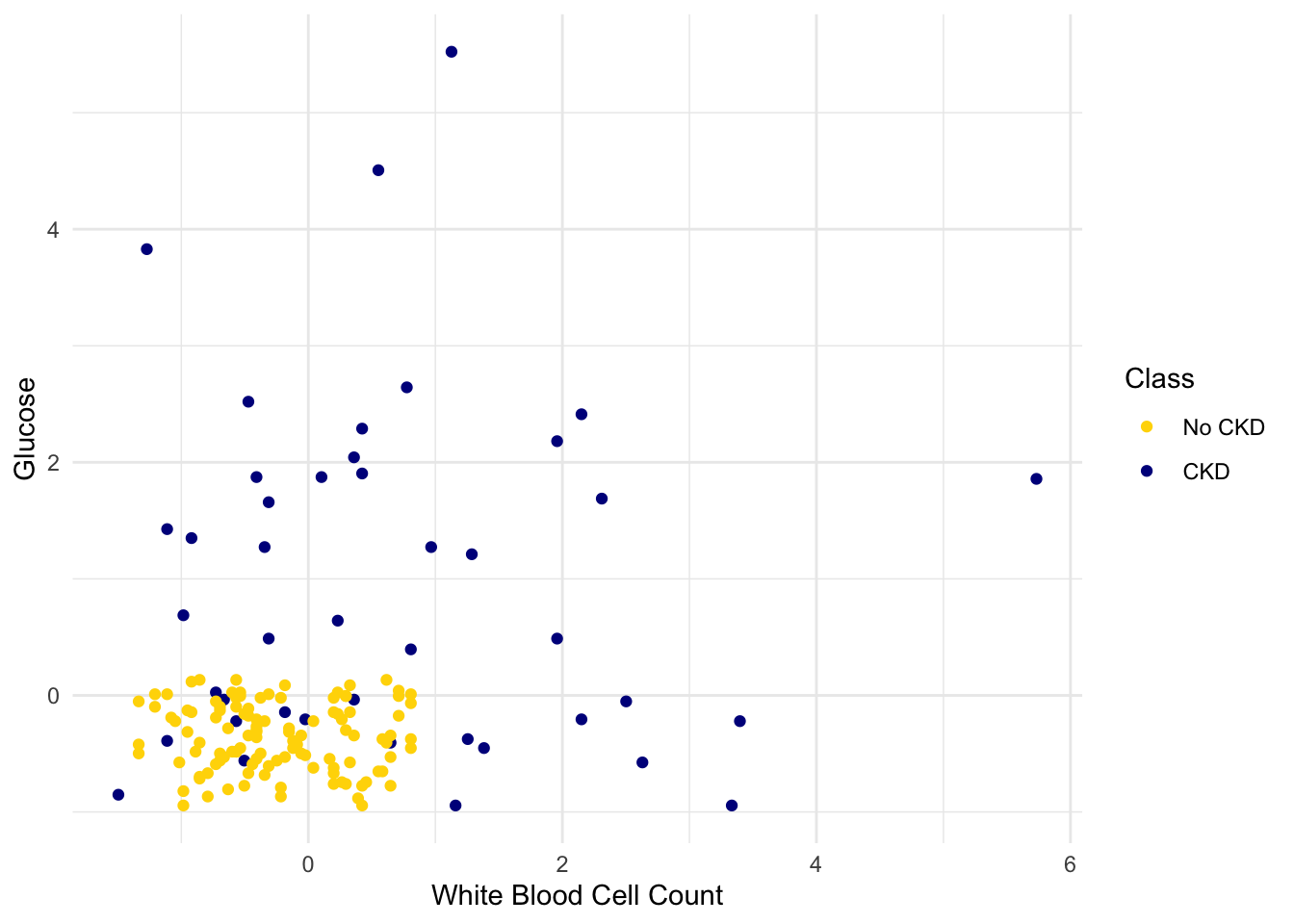
As you can see, non-CKD individuals are all clustered in the lower-left. Most of the patients with CKD are above or to the right of that cluster… but not all. There are some patients with CKD who are in the lower left of the above figure (as indicated by the handful of blue dots scattered among the gold cluster). What this means is that you can’t tell for certain whether someone has CKD from just these two blood test measurements.
If we are given Alice’s glucose level and white blood cell count, can we predict whether she has CKD? Yes, we can make a prediction, but we shouldn’t expect it to be 100% accurate. Intuitively, it seems like there’s a natural strategy for predicting: plot where Alice lands in the scatter plot; if she is in the lower-left, predict that she doesn’t have CKD, otherwise predict she has CKD.
This isn’t perfect – our predictions will sometimes be wrong. (Take a minute and think it through: for which patients will it make a mistake?) As the scatterplot above indicates, sometimes people with CKD have glucose and white blood cell levels that look identical to those of someone without CKD, so any classifier is inevitably going to make the wrong prediction for them.
Can we automate this on a computer? Well, the nearest neighbor classifier would be a reasonable choice here too. Take a minute and think it through: how will its predictions compare to those from the intuitive strategy above? When will they differ?
Its predictions will be pretty similar to our intuitive strategy, but occasionally it will make a different prediction. In particular, if Alice’s blood test results happen to put her right near one of the blue dots in the lower-left, the intuitive strategy would predict ‘not CKD’, whereas the nearest neighbor classifier will predict ‘CKD’.
There is a simple generalization of the nearest neighbor classifier that fixes this anomaly. It is called the k-nearest neighbor classifier. To predict Alice’s diagnosis, rather than looking at just the one neighbor closest to her, we can look at the 3 points that are closest to her, and use the diagnosis for each of those 3 points to predict Alice’s diagnosis. In particular, we’ll use the majority value among those 3 diagnoses as our prediction for Alice’s diagnosis. Of course, there’s nothing special about the number 3: we could use 4, or 5, or more. (It’s often convenient to pick an odd number, so that we don’t have to deal with ties.) In general, we pick a number \(k\), and our predicted diagnosis for Alice is based on the \(k\) patients in the training set who are closest to Alice. Intuitively, these are the \(k\) patients whose blood test results were most similar to Alice, so it seems reasonable to use their diagnoses to predict Alice’s diagnosis.
The \(k\)-nearest neighbor classifier will now behave just like our intuitive strategy above.
The decision boundary is where the classifier switches from turning the red points blue to turning them gold.
1.2 Training and Testing
How good is our nearest neighbor classifier? To answer this we’ll need to find out how frequently our classifications are correct. If a patient has chronic kidney disease, how likely is our classifier to pick that up?
If the patient is in our training set, we can find out immediately. We already know what class the patient is in. So we can just compare our prediction and the patient’s true class.
But the point of the classifier is to make predictions for new patients not in our training set. We don’t know what class these patients are in but we can make a prediction based on our classifier. How to find out whether the prediction is correct?
One way is to wait for further medical tests on the patient and then check whether or not our prediction agrees with the test results. With that approach, by the time we can say how likely our prediction is to be accurate, it is no longer useful for helping the patient.
Instead, we will try our classifier on some patients whose true classes are known. Then, we will compute the proportion of the time our classifier was correct. This proportion will serve as an estimate of the proportion of all new patients whose class our classifier will accurately predict. This is called testing.
1.2.1 Overly Optimistic “Testing”
The training set offers a very tempting set of patients on whom to test out our classifier, because we know the class of each patient in the training set.
But let’s be careful … there will be pitfalls ahead if we take this path. An example will show us why.
Suppose we use a 1-nearest neighbor classifier to predict whether a patient has chronic kidney disease, based on glucose and white blood cell count.
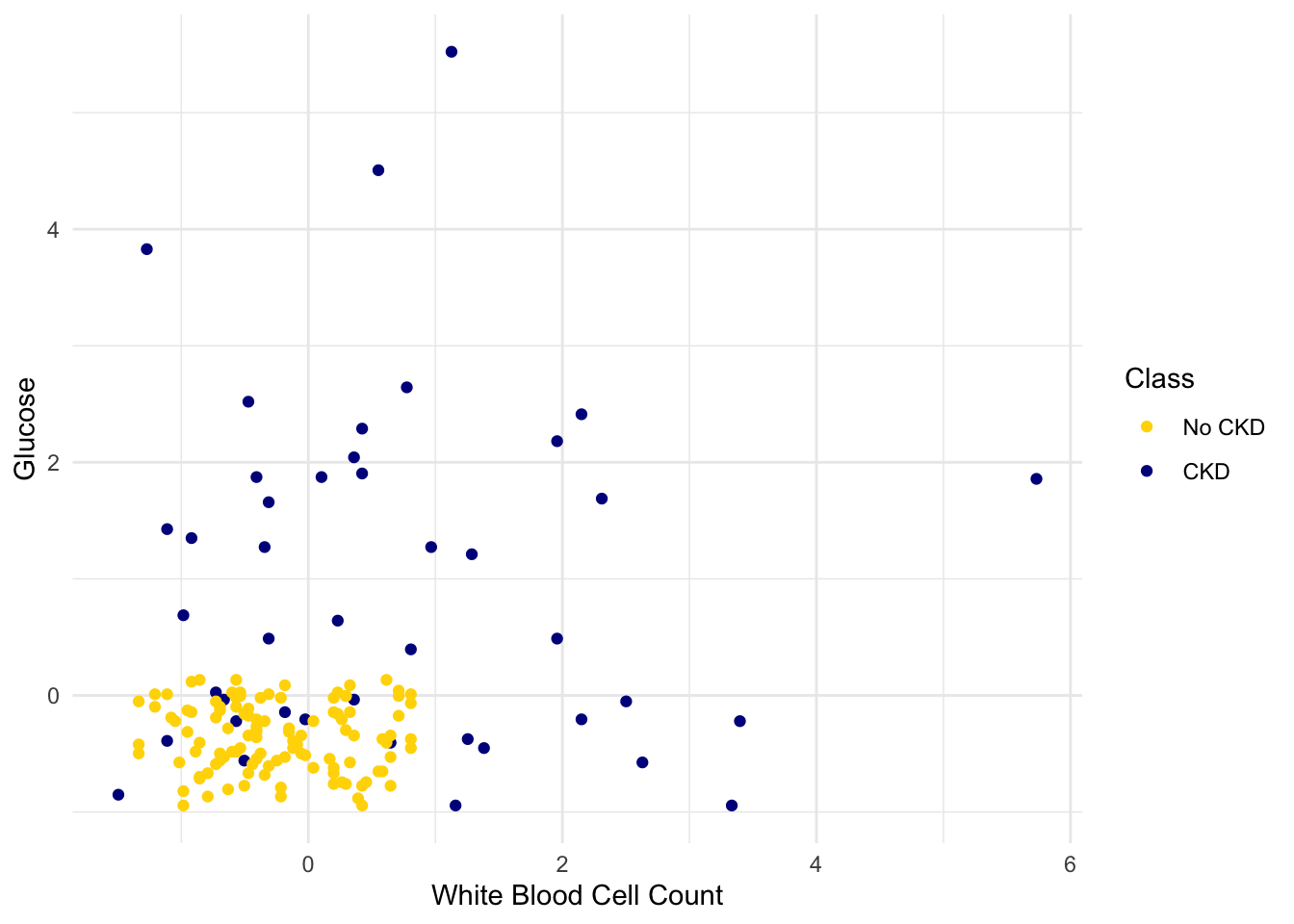
Earlier, we said that we expect to get some classifications wrong, because there’s some intermingling of blue and gold points in the lower-left.
But what about the points in the training set, that is, the points already on the scatter? Will we ever mis-classify them?
The answer is no. Remember that 1-nearest neighbor classification looks for the point in the training set that is nearest to the point being classified. Well, if the point being classified is already in the training set, then its nearest neighbor in the training set is itself! And therefore it will be classified as its own color, which will be correct because each point in the training set is already correctly colored.
In other words, if we use our training set to “test” our 1-nearest neighbor classifier, the classifier will pass the test 100% of the time.
Mission accomplished. What a great classifier!
No, not so much. A new point in the lower-left might easily be mis-classified, as we noted earlier. “100% accuracy” was a nice dream while it lasted.
The lesson of this example is not to use the training set to test a classifier that is based on it.
1.2.2 Generating a Test Set
In earlier chapters, we saw that random sampling could be used to estimate the proportion of individuals in a population that met some criterion. Unfortunately, we have just seen that the training set is not like a random sample from the population of all patients, in one important respect: Our classifier guesses correctly for a higher proportion of individuals in the training set than it does for individuals in the population.
When we computed confidence intervals for numerical parameters, we wanted to have many new random samples from a population, but we only had access to a single sample. We solved that problem by taking bootstrap resamples from our sample.
We will use an analogous idea to test our classifier. We will create two samples out of the original training set, use one of the samples as our training set, and the other one for testing.
So we will have three groups of individuals: - a training set on which we can do any amount of exploration to build our classifier; - a separate testing set on which to try out our classifier and see what fraction of times it classifies correctly; - the underlying population of individuals for whom we don’t know the true classes; the hope is that our classifier will succeed about as well for these individuals as it did for our testing set.
How to generate the training and testing sets? You’ve guessed it – we’ll select at random.
There are 158 individuals in ckd. Let’s use a random half of them for training and the other half for testing. To do this, we’ll shuffle all the rows, take the first 79 as the training set, and the remaining 79 for testing.
# Samples and shuffles 100% of the data
shuffled_ckd <- ckd |> slice_sample(prop = 1)
training <- shuffled_ckd |> slice(1:79)
testing <- shuffled_ckd |> slice(80:158)Now let’s construct our classifier based on the points in the training sample:
ggplot(training, aes(x = `White Blood Cell Count`, y = Glucose, color = Class)) +
geom_point() +
scale_color_manual(values = c("No CKD" = "gold", "CKD" = "darkblue")) +
theme_minimal()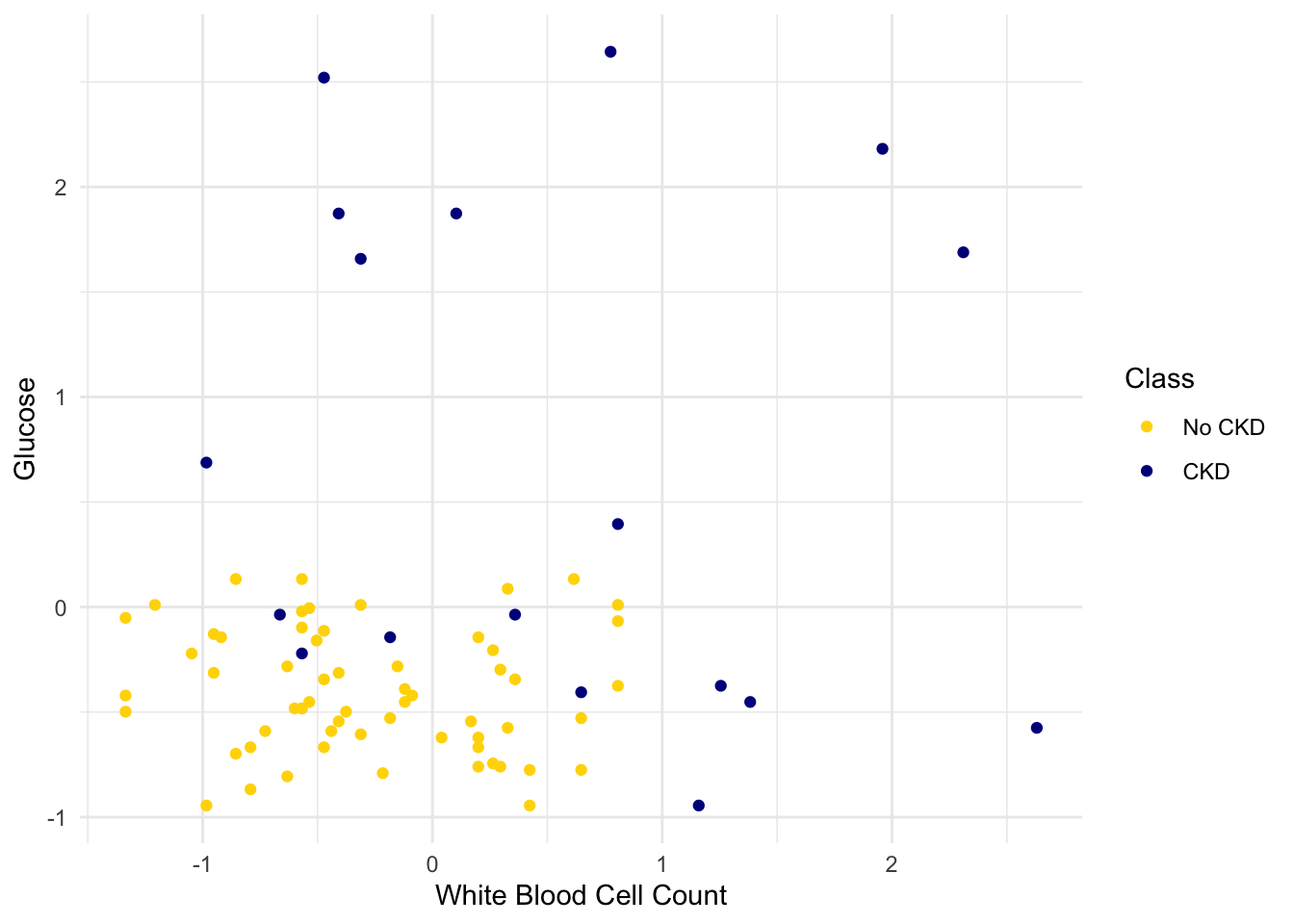
We get the following classification regions and decision boundary:
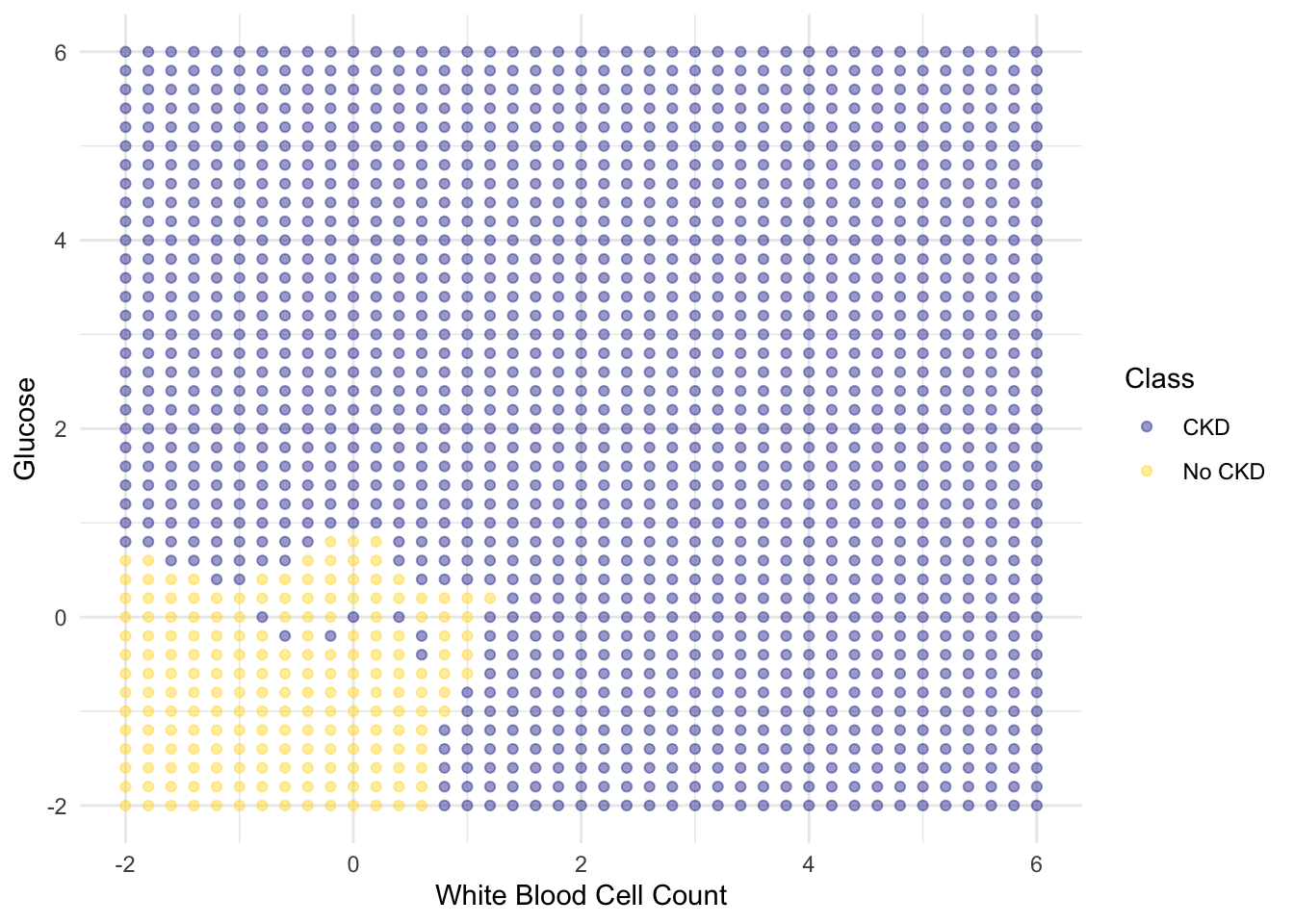
Place the test data on this graph and you can see at once that while the classifier got almost all the points right, there are some mistakes. For example, some blue points of the test set fall in the gold region of the classifier.
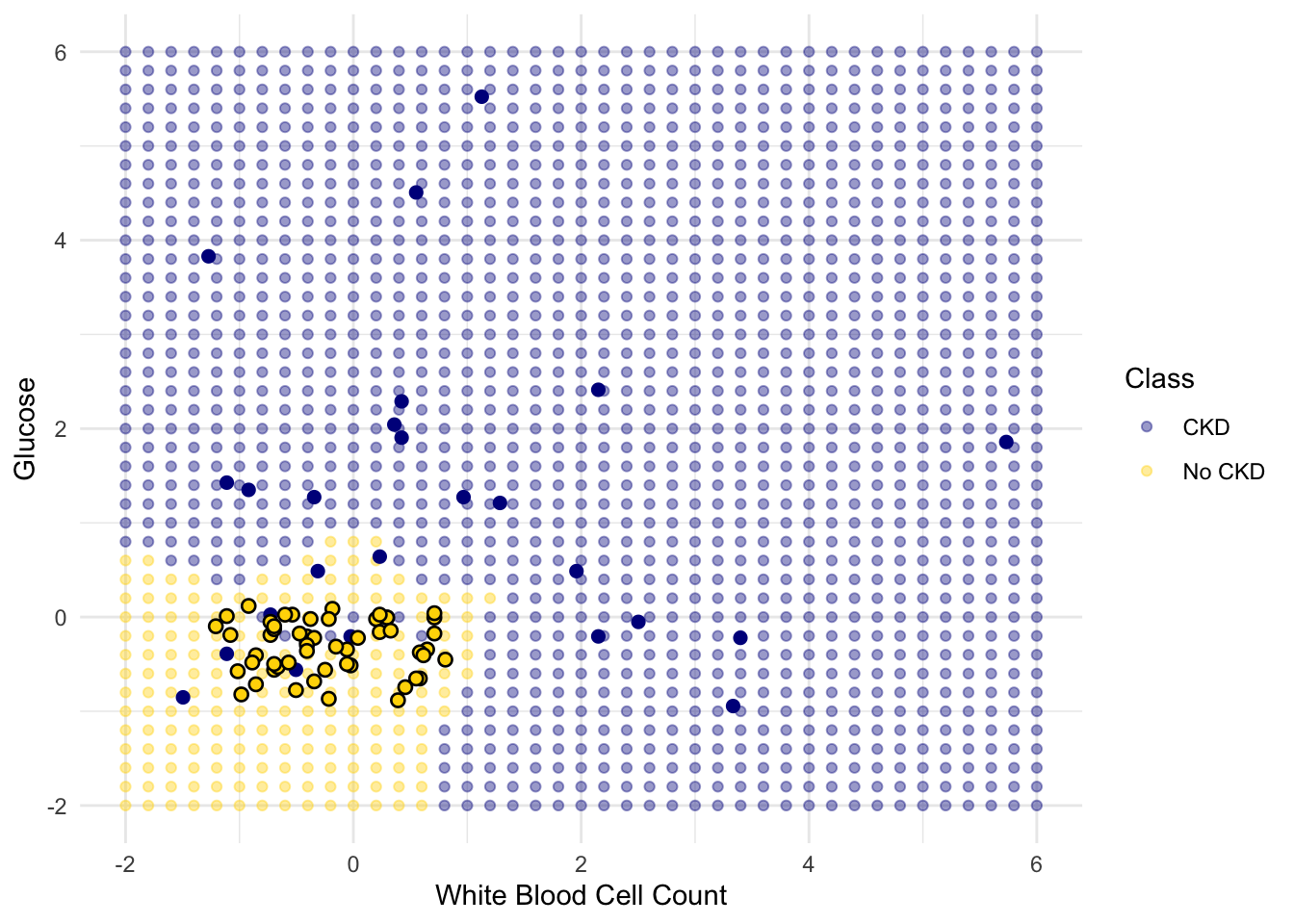
Some errors notwithstanding, it looks like the classifier does fairly well on the test set. Assuming that the original sample was drawn randomly from the underlying population, the hope is that the classifier will perform with similar accuracy on the overall population, since the test set was chosen randomly from the original sample.
1.3 Rows of Tables
Now that we have a qualitative understanding of nearest neighbor classification, it’s time to implement our classifier.
Until this chapter, we have worked mostly with single columns of tables. But now we have to see whether one individual is “close” to another. Data for individuals are contained in rows of tables.
So let’s start by taking a closer look at the rows.
Here is the original table ckd containing data on patients who were tested for chronic kidney disease.
The data corresponding to the first patient is in row 1 of the table. The tidyverse function slice() accesses the row by taking the index of the row as its argument:
Age Blood Pressure Specific Gravity
"48" "70" "1.005"
Albumin Sugar Red Blood Cells
"4" "0" "normal"
Pus Cell Pus Cell clumps Bacteria
"abnormal" "present" "notpresent"
Glucose Blood Urea Serum Creatinine
"117" "56" "3.8"
Sodium Potassium Hemoglobin
"111" "2.5" "11.2"
Packed Cell Volume White Blood Cell Count Red Blood Cell Count
"32" "6700" "3.9"
Hypertension Diabetes Mellitus Coronary Artery Disease
"yes" "no" "no"
Appetite Pedal Edema Anemia
"poor" "yes" "yes"
Class
"1" Rows are in general not vectors, as their elements can be of different types. For example, some of the elements of the row above are characters (like "abnormal") and some are numerics. So the row can’t be converted into a vector.
However, rows share some characteristics with vectors. You can use pull() to access a particular element of a row. For example, to access the Albumin level of Patient 1, we can look at the labels in the printout of the row above to find that it’s item 4:
1.3.1 Converting Rows to Vectors (When Possible)
Rows whose elements are all numerics (or all characters) can be converted to vectors. Converting a row to a vector gives us access to arithmetic operations and other nice NumPy functions, so it is often useful.
Recall that in the previous section we tried to classify the patients as ‘CKD’ or ‘not CKD’, based on two attributes Hemoglobin and Glucose, both measured in standard units.
| Hemoglobin | Glucose | Class |
|---|---|---|
| -0.863 | -0.221 | CKD |
| -1.453 | -0.945 | CKD |
| -1.002 | 3.829 | CKD |
| -2.806 | 0.395 | CKD |
| -2.077 | 0.641 | CKD |
| -1.349 | -0.560 | CKD |
| -0.412 | 2.043 | CKD |
| -1.279 | -0.945 | CKD |
| -1.106 | 1.873 | CKD |
| -1.349 | 0.488 | CKD |
Showing 10 of 158 rowsHere is a scatter plot of the two attributes, along with a red point corresponding to Alice, a new patient. Her value of hemoglobin is 0 (that is, at the average) and glucose 1.1 (that is, 1.1 SDs above average).
alice_df <- tibble(
Hemoglobin = 0,
Glucose = 1.1
)
ggplot(ckd, aes(x = Hemoglobin, y = Glucose, color = Class)) +
geom_point() +
geom_point(data = alice_df, aes(Hemoglobin, Glucose), color = "red", size = 3) +
scale_color_manual(values = c("No CKD" = "gold", "CKD" = "darkblue")) +
theme_minimal()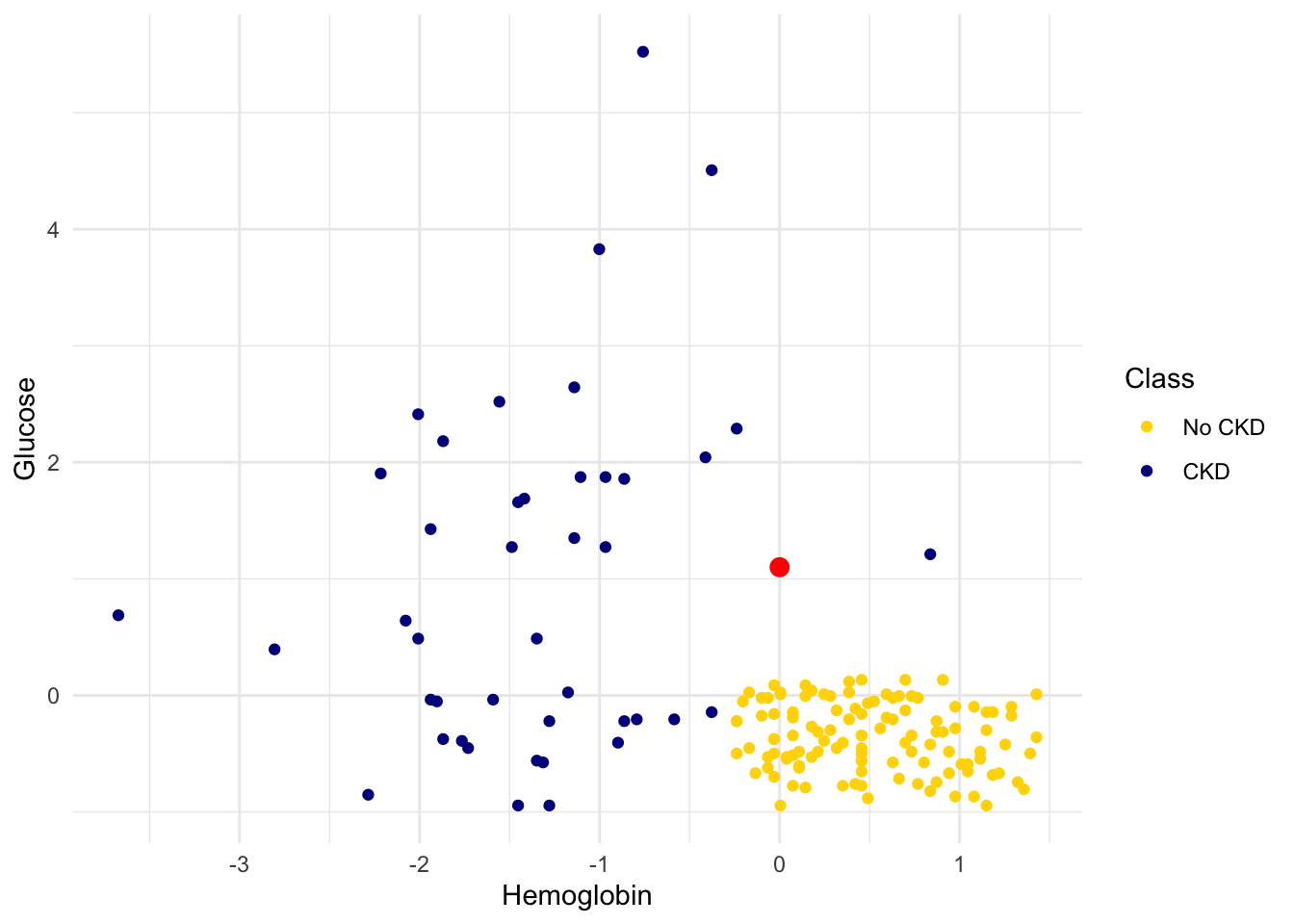
To find the distance between Alice’s point and any of the other points, we only need the values of the attributes:
ckd_attributes <- ckd |> select(Hemoglobin, Glucose)
ckd_attributes# A tibble: 158 × 2
Hemoglobin Glucose
<dbl> <dbl>
1 -0.863 -0.221
2 -1.45 -0.945
3 -1.00 3.83
4 -2.81 0.395
5 -2.08 0.641
6 -1.35 -0.560
7 -0.412 2.04
8 -1.28 -0.945
9 -1.11 1.87
10 -1.35 0.488
# ℹ 148 more rowsEach row consists of the coordinates of one point in our training sample. Because the rows now consist only of numerical values, it is possible to convert them to vectors of numerics. For this, we use the function as.numeric(), which converts any kind of sequential object, like a row, to a vector of numerics.
ckd_attributes |> slice(4) |> as.numeric()[1] -2.8059574 0.3951077This is very handy because we can now use vector operations on the data in each row.
1.4 Implementing the Classifier
We are now ready to implement a \(k\)-nearest neighbor classifier using R and the tidymodels ecosystem. We have used only two attributes so far, for ease of visualization. But usually predictions will be based on many attributes. Here is an example that shows how multiple attributes can be better than pairs. Let’s load our useful libraries.
1.4.1 Banknote authentication
This time we’ll look at predicting whether a banknote (e.g., a \$20 bill) is counterfeit or legitimate. Researchers have put together a data set for us, based on photographs of many individual banknotes: some counterfeit, some legitimate. They computed a few numbers from each image, using techniques that we won’t worry about for this course. So, for each banknote, we know a few numbers that were computed from a photograph of it as well as its class (whether it is counterfeit or not). Let’s load it into a table and take a look.
banknotes <- read_csv('data/banknote.csv')
banknotes# A tibble: 1,372 × 5
WaveletVar WaveletSkew WaveletCurt Entropy Class
<dbl> <dbl> <dbl> <dbl> <dbl>
1 3.62 8.67 -2.81 -0.447 0
2 4.55 8.17 -2.46 -1.46 0
3 3.87 -2.64 1.92 0.106 0
4 3.46 9.52 -4.01 -3.59 0
5 0.329 -4.46 4.57 -0.989 0
6 4.37 9.67 -3.96 -3.16 0
7 3.59 3.01 0.729 0.564 0
8 2.09 -6.81 8.46 -0.602 0
9 3.20 5.76 -0.753 -0.613 0
10 1.54 9.18 -2.27 -0.735 0
# ℹ 1,362 more rowsThe Class column of 0s in 1s corresponds to Legitmate an Fraudulent bank notes. We will use factor() to categorize them accordingly.
Let’s look at whether the first two numbers tell us anything about whether the banknote is counterfeit or not. Here’s a scatterplot:
ggplot(banknotes, aes(x = WaveletVar, y = WaveletCurt, color = Class)) +
scale_color_manual(values = c("Legitimate" = "gold", "Fraudulent" = "darkblue")) +
geom_point(alpha = 0.7) +
labs(x = "Wavelet variance", y = "Wavelet curtosis", color = "Class")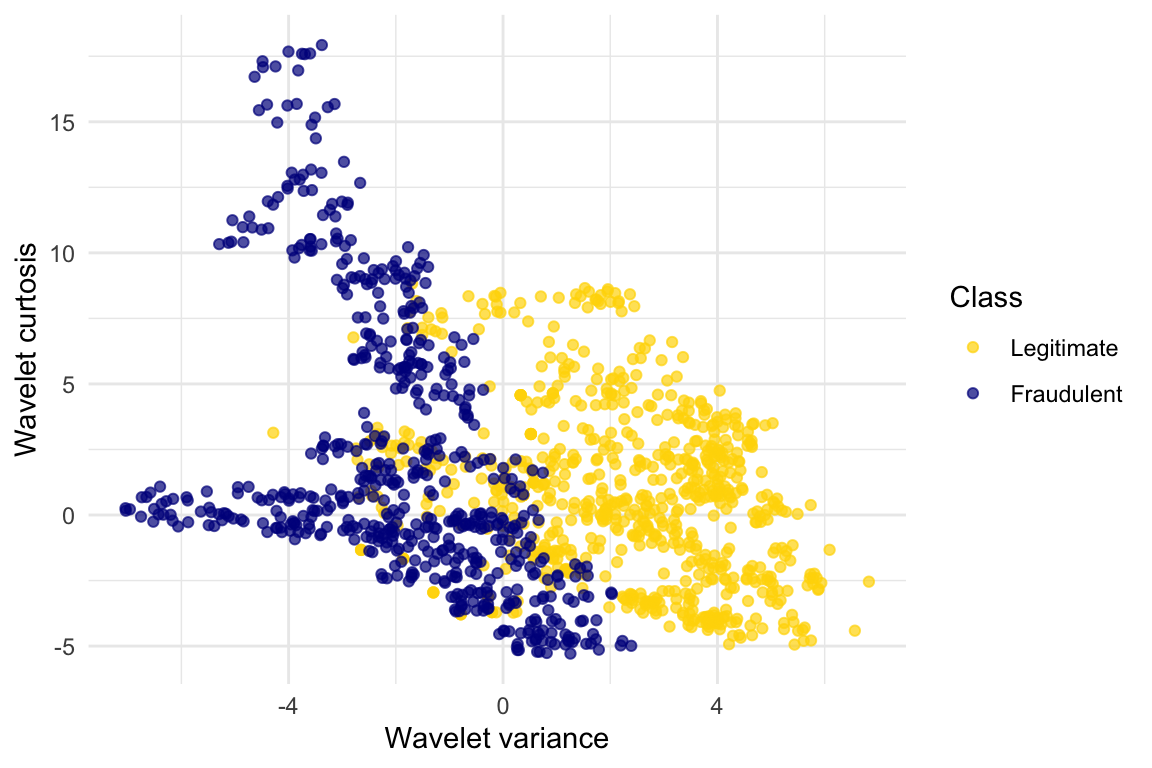
ggplot(banknotes, aes(x = WaveletVar, y = WaveletCurt, color = Class)) +
scale_color_manual(values = c("Legitimate" = "gold", "Fraudulent" = "darkblue")) +
geom_point(alpha = 0.7) 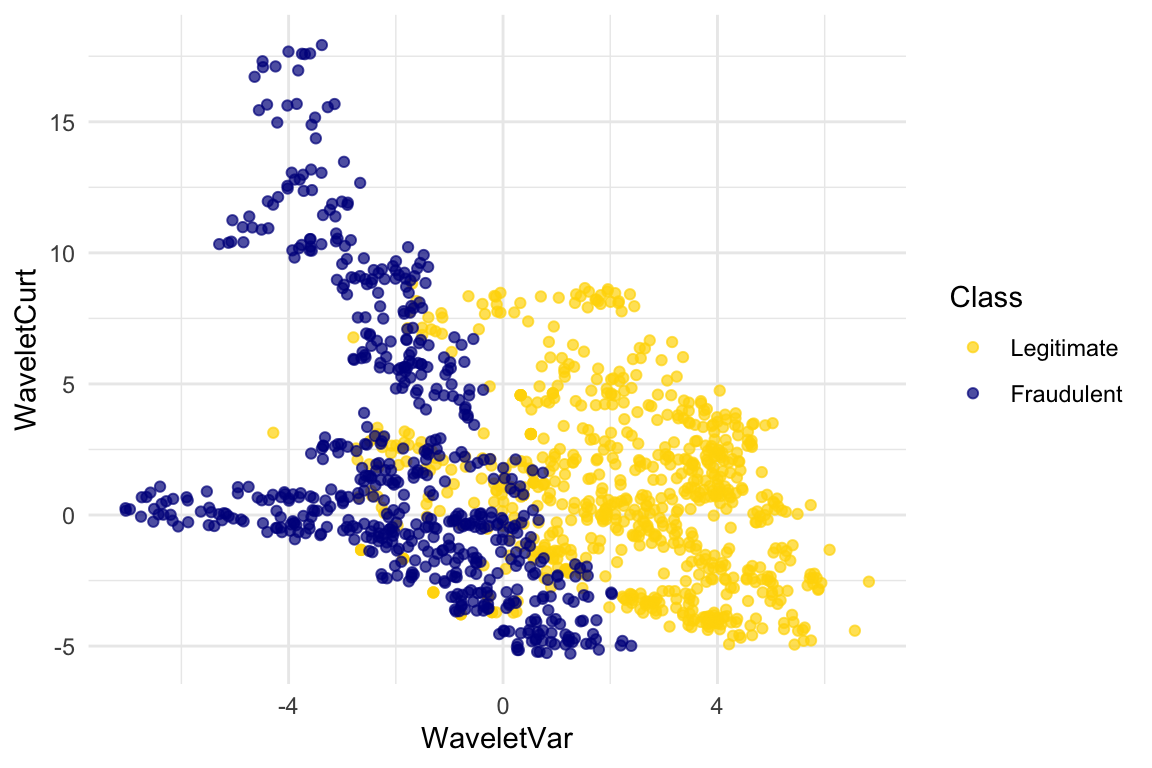
Pretty interesting! Those two measurements do seem helpful for predicting whether the banknote is counterfeit or not. However, in this example you can now see that there is some overlap between the blue cluster and the gold cluster. This indicates that there will be some images where it’s hard to tell whether the banknote is legitimate based on just these two numbers. Still, you could use a \(k\)-nearest neighbor classifier to predict the legitimacy of a banknote.
Take a minute and think it through: Suppose we used \(k=11\) (say). What parts of the plot would the classifier get right, and what parts would it make errors on? What would the decision boundary look like?
The patterns that show up in the data can get pretty wild. For instance, here’s what we’d get if used a different pair of measurements from the images:
ggplot(banknotes, aes(x = WaveletSkew, y = Entropy, color = Class)) +
scale_color_manual(values = c("Legitimate" = "gold", "Fraudulent" = "darkblue")) +
geom_point(alpha = 0.7)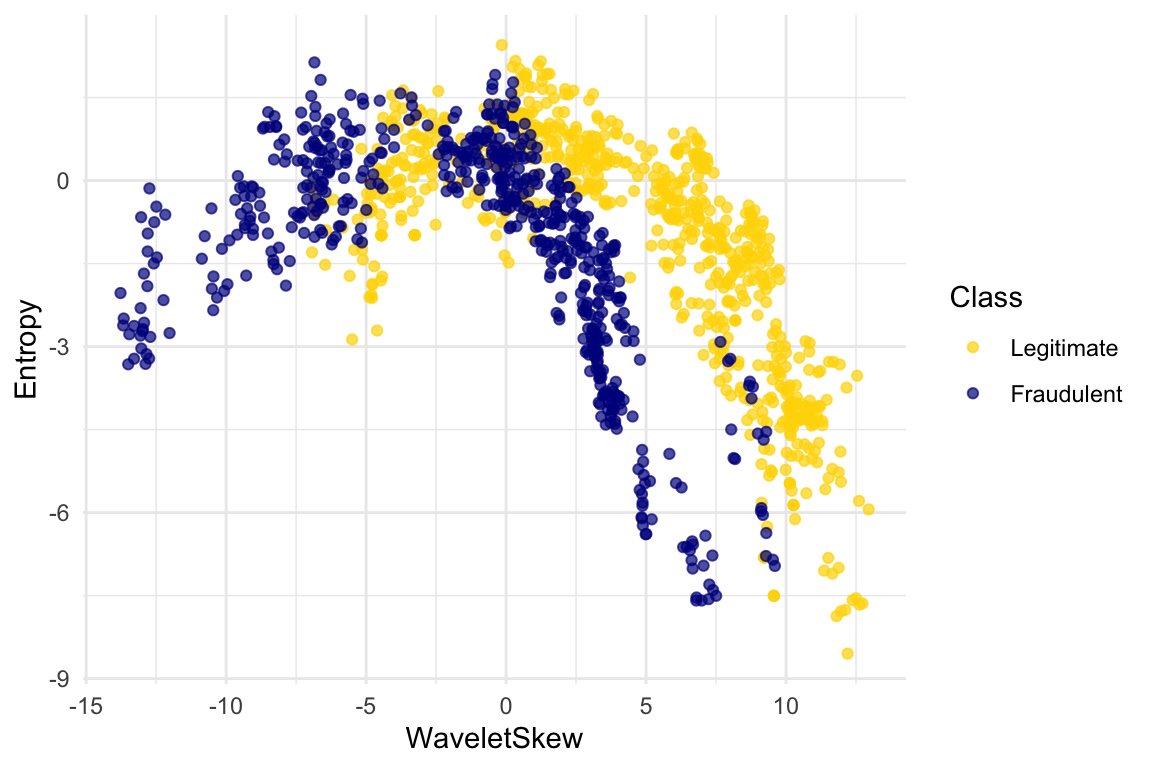
There does seem to be a pattern, but it’s a pretty complex one. Nonetheless, the \(k\)-nearest neighbors classifier can still be used and will effectively “discover” patterns out of this. This illustrates how powerful machine learning can be: it can effectively take advantage of even patterns that we would not have anticipated, or that we would have thought to “program into” the computer.
1.4.2 Multiple attributes
So far I’ve been assuming that we have exactly 2 attributes that we can use to help us make our prediction. What if we have more than 2? For instance, what if we have 3 attributes?
Here’s the cool part: you can use the same ideas for this case, too. All you have to do is make a 3-dimensional scatterplot, instead of a 2-dimensional plot. You can still use the \(k\)-nearest neighbors classifier, but now computing distances in 3 dimensions instead of just 2. It just works. Very cool!
In fact, there’s nothing special about 2 or 3. If you have 4 attributes, you can use the \(k\)-nearest neighbors classifier in 4 dimensions. 5 attributes? Work in 5-dimensional space. And no need to stop there! This all works for arbitrarily many attributes; you just work in a very high dimensional space. It gets wicked-impossible to visualize, but that’s OK. The computer algorithm generalizes very nicely: all you need is the ability to compute the distance, and that’s not hard. Mind-blowing stuff!
For instance, let’s see what happens if we try to predict whether a banknote is counterfeit or not using 3 of the measurements, instead of just 2. Here’s what you get:
library(plotly)
plot_ly(
data = banknotes,
x = ~WaveletSkew,
y = ~WaveletVar,
z = ~WaveletCurt,
color = ~Class,
colors = viridis::viridis(2),
type = "scatter3d",
mode = "markers",
marker = list(size = 4, opacity = 0.7)
)Use the plotly tools to pan around and view the points from different angles. You’ll find with just 2 attributes, there was some overlap between the two clusters (which means that the classifier was bound to make some mistakes for pointers in the overlap). But when we use these 3 attributes, the two clusters have almost no overlap. In other words, a classifier that uses these 3 attributes will be more accurate than one that only uses the 2 attributes.
This is a general phenomenom in classification. Each attribute can potentially give you new information, so more attributes sometimes helps you build a better classifier. Of course, the cost is that now we have to gather more information to measure the value of each attribute, but this cost may be well worth it if it significantly improves the accuracy of our classifier.
To sum up: you now know how to use \(k\)-nearest neighbor classification to predict the answer to a yes/no question, based on the values of some attributes, assuming you have a training set with examples where the correct prediction is known. The general roadmap is this:
- identify some attributes that you think might help you predict the answer to the question.
- Gather a training set of examples where you know the values of the attributes as well as the correct prediction.
- To make predictions in the future, measure the value of the attributes and then use \(k\)-nearest neighbor classification to predict the answer to the question.
1.4.3 Distance in Multiple Dimensions
We know how to compute distance in 2-dimensional space. If we have a point at coordinates \((x_0,y_0)\) and another at \((x_1,y_1)\), the distance between them is
\[D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2}.\]
In 3-dimensional space, the points are \((x_0, y_0, z_0)\) and \((x_1, y_1, z_1)\), and the formula for the distance between them is
\[ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2 + (z_0-z_1)^2} \]
In \(n\)-dimensional space, things are a bit harder to visualize, but I think you can see how the formula generalized: we sum up the squares of the differences between each individual coordinate, and then take the square root of that.
1.4.4 Wine Example
In the last section, we defined the function distance which returned the distance between two points. We used it in two-dimensions, but the great news is that the function doesn’t care how many dimensions there are! It just subtracts the two arrays of coordinates (no matter how long the arrays are), squares the differences and adds up, and then takes the square root. To work in multiple dimensions, we don’t have to change the code at all.
Let’s use this on a new dataset. The table wine contains the chemical composition of 178 different Italian wines. The classes are the grape species, called cultivars. There are three classes but let’s just see whether we can tell Class 1 apart from the other two.
wine <- read_csv('data/wine.csv') |>
mutate(
Class = factor(if_else(Class == 1, 1, 0),
levels = c(0, 1),
labels = c("Other Classes", "Class 1"))
)
wine# A tibble: 178 × 14
Class Alcohol `Malic Acid` Ash `Alcalinity of Ash` Magnesium
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Class 1 14.2 1.71 2.43 15.6 127
2 Class 1 13.2 1.78 2.14 11.2 100
3 Class 1 13.2 2.36 2.67 18.6 101
4 Class 1 14.4 1.95 2.5 16.8 113
5 Class 1 13.2 2.59 2.87 21 118
6 Class 1 14.2 1.76 2.45 15.2 112
7 Class 1 14.4 1.87 2.45 14.6 96
8 Class 1 14.1 2.15 2.61 17.6 121
9 Class 1 14.8 1.64 2.17 14 97
10 Class 1 13.9 1.35 2.27 16 98
# ℹ 168 more rows
# ℹ 8 more variables: `Total Phenols` <dbl>, Flavanoids <dbl>,
# `Nonflavanoid phenols` <dbl>, Proanthocyanins <dbl>,
# `Color Intensity` <dbl>, Hue <dbl>, `OD280/OD315 of diulted wines` <dbl>,
# Proline <dbl>The first two wines are both in Class 1. To find the distance between them, we first need a table of just the attributes:
wine_attributes <- wine |>
select(-Class)
distance(wine_attributes[1, ], wine_attributes[2, ])[1] 31.26501The last wine in the table is of Class 0. Its distance from the first wine is:
distance(as.numeric(wine_attributes[1, ]), as.numeric(wine_attributes[nrow(wine_attributes), ]))[1] 506.0594That’s quite a bit bigger! Let’s do some visualization to see if Class 1 really looks different from Class 0.
ggplot(wine, aes(x = Flavanoids, y = Alcohol, color = Class)) +
scale_color_manual(values = c("Other Classes" = "gold", "Class 1" = "darkblue")) +
geom_point(alpha = 0.7)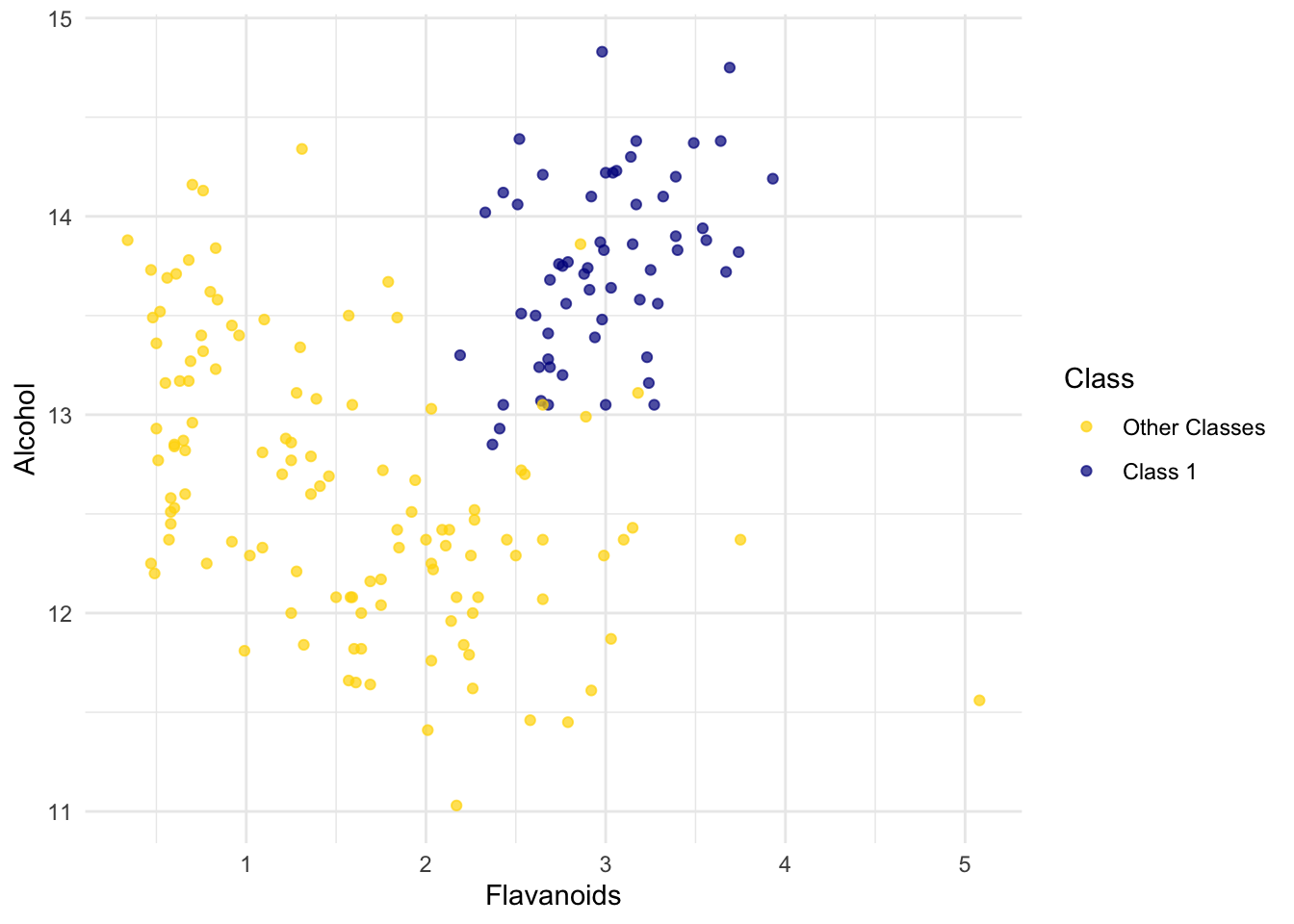
The blue points (Class 1) are almost entirely separate from the gold ones. That is one indication of why the distance between two Class 1 wines would be smaller than the distance between wines of two different classes. We can see a similar phenomenon with a different pair of attributes too:
ggplot(wine, aes(x = `Alcalinity of Ash`, y = Ash, color = Class)) +
scale_color_manual(values = c("Other Classes" = "gold", "Class 1" = "darkblue")) +
geom_point(alpha = 0.7)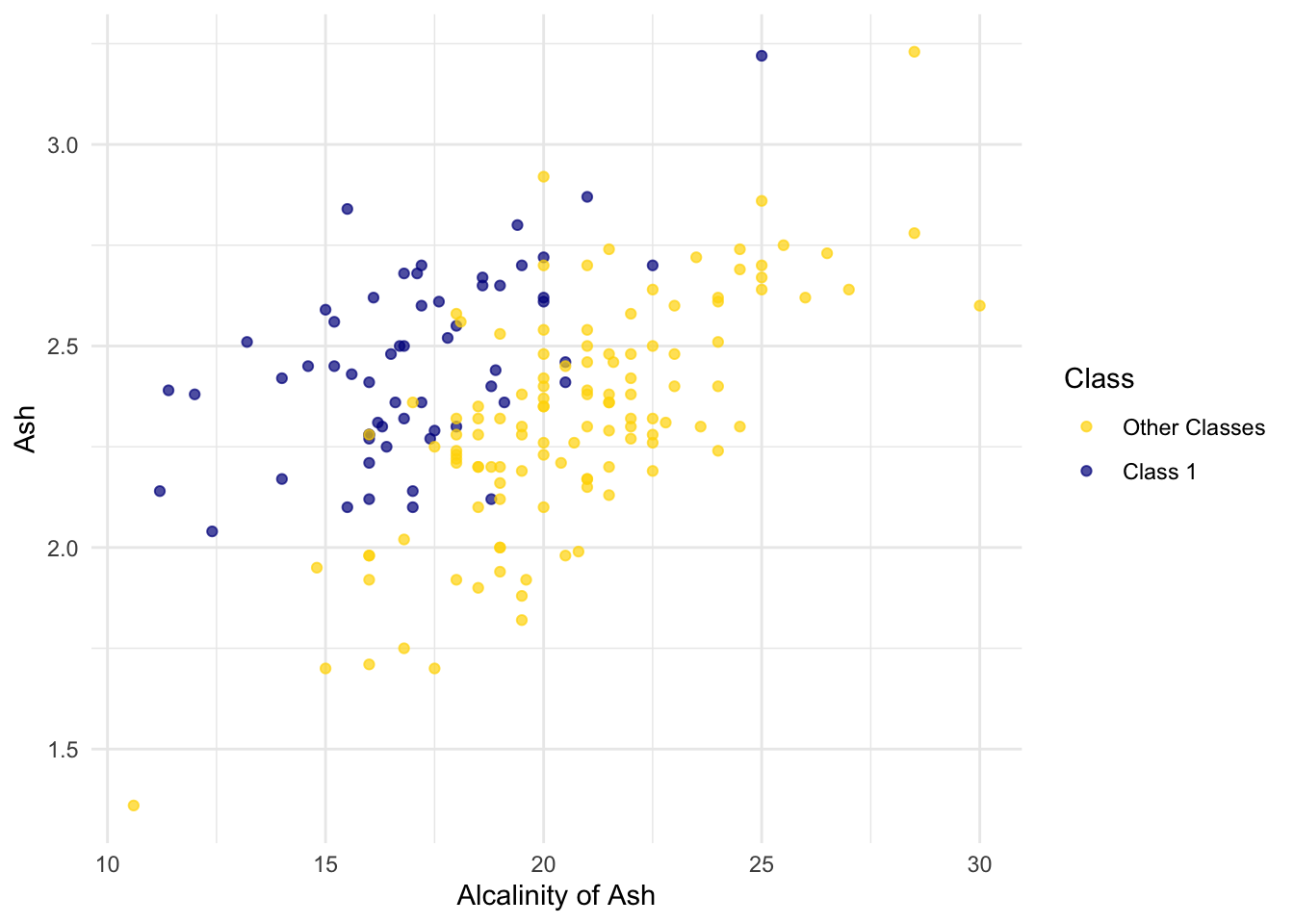
But for some pairs the picture is more murky.
ggplot(wine, aes(x = Magnesium, y = `Total Phenols`, color = Class)) +
scale_color_manual(values = c("Other Classes" = "gold", "Class 1" = "darkblue")) +
geom_point(alpha = 0.7)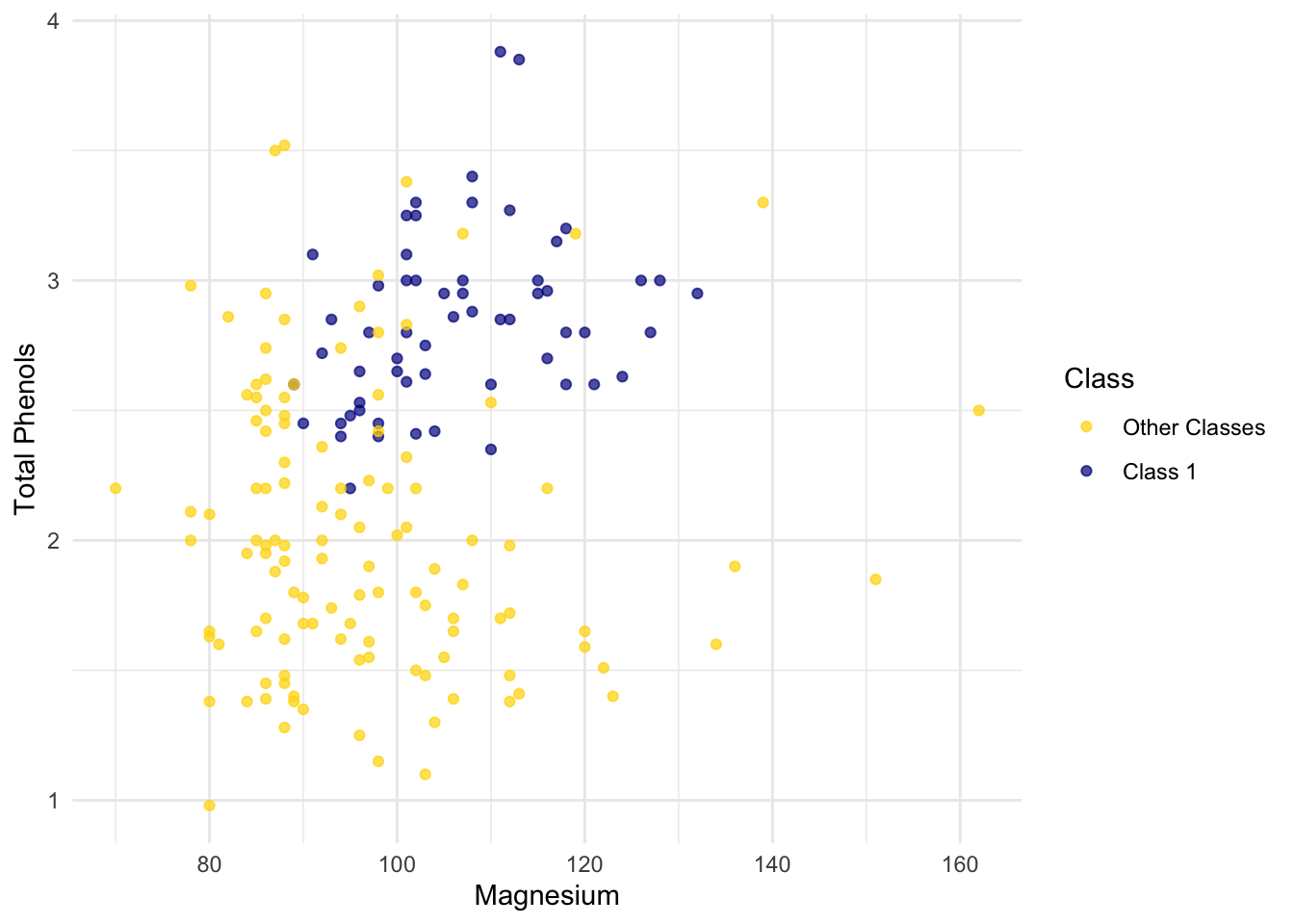
Let’s see if we can implement a classifier based on all of the attributes. After that, we’ll see how accurate it is.
1.4.5 Implementation Idea
We will use the tidymodels framerwork to implement the classifier and use it to predict a new point. The classifier works by finding the \(k\) nearest neighbors of point from the training set. The underlying approach is like this:
Find the closest \(k\) neighbors of
point, i.e., the \(k\) wines from the training set that are most similar topoint.Look at the classes of those \(k\) neighbors, and take the majority vote to find the most-common class of wine. Use that as our predicted class for
point.
1.4.6 Implementation with tidymodels
Set up the model specification. Here we choose the k-nearest neighbors algorithm using the 5 nearest neighbors, use the kknn engine (an implementation of k-NN), and set the mode to classification because we want to predict a class label.
knn_spec <- nearest_neighbor(neighbors = 5) |>
set_engine("kknn") |>
set_mode("classification")Next, we define how the model should learn from the data.Class ~ . means “use all columns except Class as predictors.”
knn_fit <- knn_spec |>
fit(Class ~ ., data = wine)Now we can plug in a row of predictor values to make a prediction:
special_wine <- wine_attributes[1, ]
predict(knn_fit, new_data = special_wine)# A tibble: 1 × 1
.pred_class
<fct>
1 Class 1 If we change special_wine to be the last one in the dataset, is our classifier able to tell that it’s in Other Classes?
# A tibble: 1 × 1
.pred_class
<fct>
1 Other ClassesYes! The classifier gets this one right too.
But we don’t yet know how it does with all the other wines, and in any case we know that testing on wines that are already part of the training set might be over-optimistic. In the final section of this chapter, we will separate the wines into a training and test set and then measure the accuracy of our classifier on the test set.
1.5 The Accuracy of the Classifier
To see how well our classifier does, we might put 50% of the data into the training set and the other 50% into the test set. Basically, we are setting aside some data for later use, so we can use it to measure the accuracy of our classifier. We’ve been calling that the test set. Sometimes people will call the data that you set aside for testing a hold-out set, and they’ll call this strategy for estimating accuracy the hold-out method.
Note that this approach requires great discipline. Before you start applying machine learning methods, you have to take some of your data and set it aside for testing. You must avoid using the test set for developing your classifier: you shouldn’t use it to help train your classifier or tweak its settings or for brainstorming ways to improve your classifier. Instead, you should use it only once, at the very end, after you’ve finalized your classifier, when you want an unbiased estimate of its accuracy.
1.5.1 Measuring the Accuracy of Our Wine Classifier
OK, so let’s apply the hold-out method to evaluate the effectiveness of the \(k\)-nearest neighbor classifier for identifying wines. The data set has 178 wines, so we’ll randomly permute the data set and put 89 of them in the training set and the remaining 89 in the test set.
data_split <- initial_split(wine, prop = 0.5, strata = Class)
train_data <- training(data_split)
test_data <- testing(data_split)Our plan is to train the classifier using the 89 wines in the training set, and evaluate how well it performs on the test set. First, we will set up the classifier. We’ll arbitrarily use \(k=5\). Then we’ll train it on the attributes and labels from train_data.
# Set up the classifier
knn_spec <- nearest_neighbor(neighbors = 5) |>
set_engine("kknn") |>
set_mode("classification")
# Train the classifier
knn_fit <- knn_spec |>
fit(Class ~ ., data = train_data)Then we can use the predict() function with the classifier stored in knn_fit. We will supply it the test_data to make a predict from. From that we get the predicted labels of Class 1 or Other Classes.
knn_preds <- predict(knn_fit, new_data = test_data)
knn_preds# A tibble: 90 × 1
.pred_class
<fct>
1 Class 1
2 Class 1
3 Class 1
4 Class 1
5 Class 1
6 Class 1
7 Class 1
8 Class 1
9 Class 1
10 Class 1
# ℹ 80 more rowsThe last past is to compare how many of these prediction are correct by looking at what the true labels are from test_data. Let’s see how we did.
test_data |>
mutate(predicted = knn_preds$.pred_class) |>
accuracy(truth = Class, estimate = predicted)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.978The accuracy rate isn’t bad at all for a simple classifier.
1.5.2 Breast Cancer Diagnosis
Now I want to do an example based on diagnosing breast cancer. It was inspired by Brittany Wenger, who won the Google national science fair in 2012 as a 17-year old high school student. Here’s Brittany:

Brittany’s science fair project was to build a classification algorithm to diagnose breast cancer. She won grand prize for building an algorithm whose accuracy was almost 99%.
Let’s see how well we can do, with the ideas we’ve learned in this course.
So, let me tell you a little bit about the data set. Basically, if a woman has a lump in her breast, the doctors may want to take a biopsy to see if it is cancerous. There are several different procedures for doing that. Brittany focused on fine needle aspiration (FNA), because it is less invasive than the alternatives. The doctor gets a sample of the mass, puts it under a microscope, takes a picture, and a trained lab tech analyzes the picture to determine whether it is cancer or not. We get a picture like one of the following:
Unfortunately, distinguishing between benign vs malignant can be tricky. So, researchers have studied the use of machine learning to help with this task. The idea is that we’ll ask the lab tech to analyze the image and compute various attributes: things like the typical size of a cell, how much variation there is among the cell sizes, and so on. Then, we’ll try to use this information to predict (classify) whether the sample is malignant or not. We have a training set of past samples from women where the correct diagnosis is known, and we’ll hope that our machine learning algorithm can use those to learn how to predict the diagnosis for future samples.
We end up with the following data set. For the “Class” column, 1 means malignant (cancer); 0 means benign (not cancer).
| Clump Thickness | Uniformity of Cell Size | Uniformity of Cell Shape | Marginal Adhesion | Single Epithelial Cell Size | Bare Nuclei | Bland Chromatin | Normal Nucleoli | Mitoses | Class |
|---|---|---|---|---|---|---|---|---|---|
| 5 | 1 | 1 | 1 | 2 | 1 | 3 | 1 | 1 | benign |
| 5 | 4 | 4 | 5 | 7 | 10 | 3 | 2 | 1 | benign |
| 3 | 1 | 1 | 1 | 2 | 2 | 3 | 1 | 1 | benign |
| 6 | 8 | 8 | 1 | 3 | 4 | 3 | 7 | 1 | benign |
| 4 | 1 | 1 | 3 | 2 | 1 | 3 | 1 | 1 | benign |
| 8 | 10 | 10 | 8 | 7 | 10 | 9 | 7 | 1 | malignant |
| 1 | 1 | 1 | 1 | 2 | 10 | 3 | 1 | 1 | benign |
| 2 | 1 | 2 | 1 | 2 | 1 | 3 | 1 | 1 | benign |
| 2 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 5 | benign |
| 4 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | benign |
Showing 10 of 683 rowsSo we have 9 different attributes. I don’t know how to make a 9-dimensional scatterplot of all of them, so I’m going to pick two and plot them:
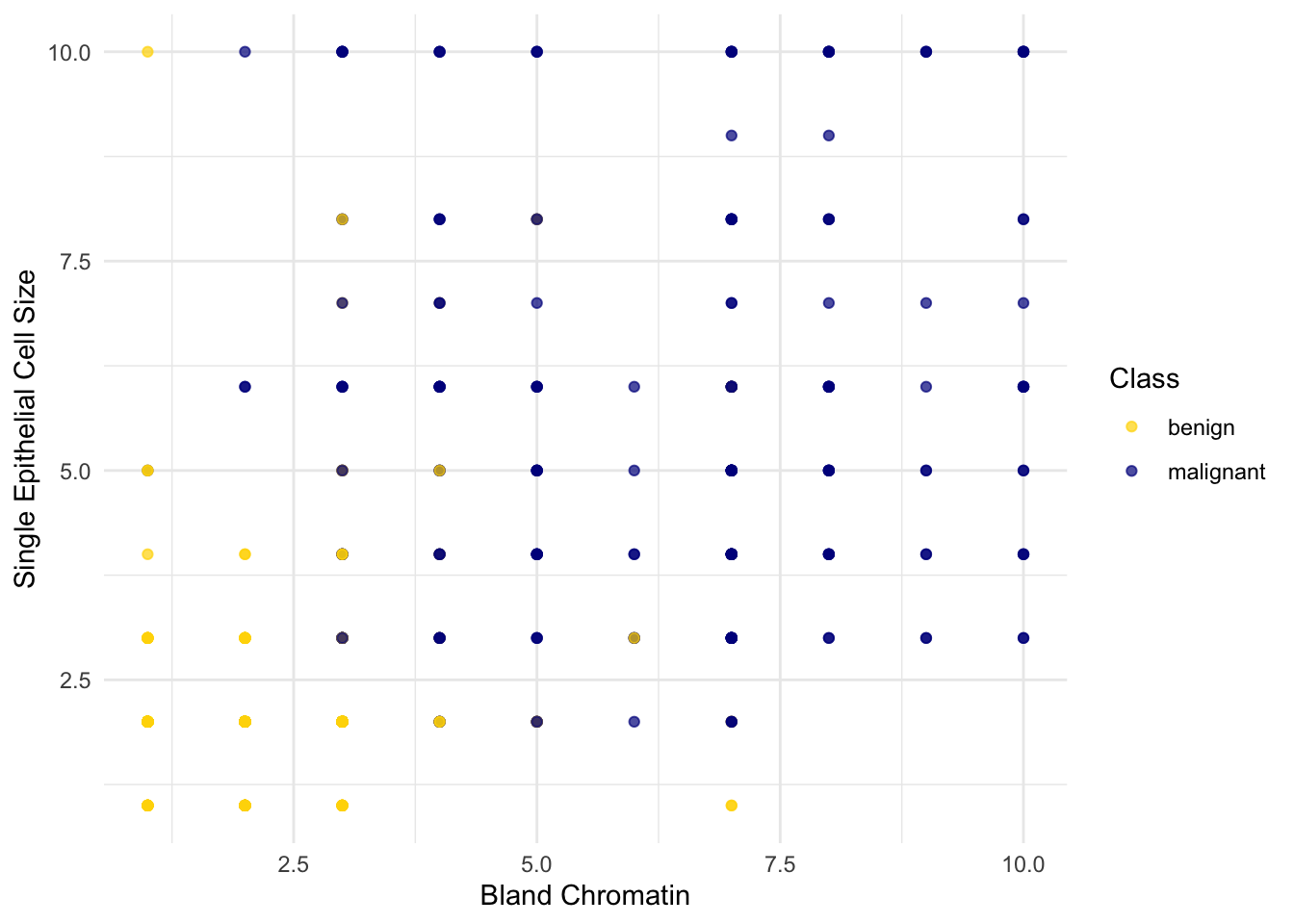
Oops. That plot is utterly misleading, because there are a bunch of points that have identical values for both the x- and y-coordinates. To make it easier to see all the data points, I’m going to add a little bit of random jitter to the x- and y-values. Here’s how that looks:
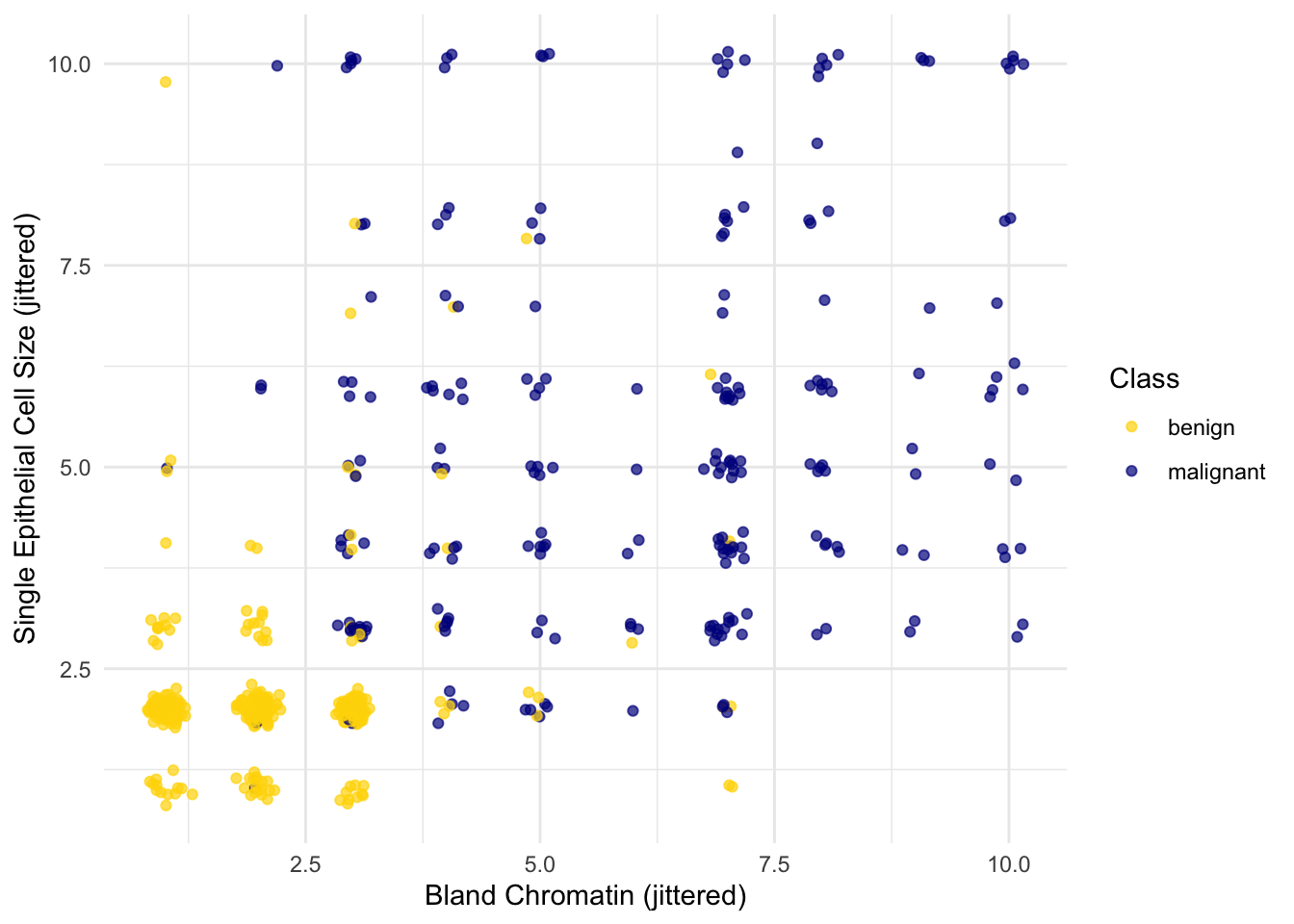
For instance, you can see there are lots of samples with chromatin = 2 and epithelial cell size = 2; all non-cancerous.
Keep in mind that the jittering is just for visualization purposes, to make it easier to get a feeling for the data. We’re ready to work with the data now, and we’ll use the original (unjittered) data.
First we’ll create a training set and a test set. The data set has 683 patients, so we’ll randomly permute the data set and put 342 of them in the training set and the remaining 341 in the test set.
data_split <- initial_split(patients, prop = 342/683, strata = Class)
train_data <- training(data_split)
test_data <- testing(data_split)Let’s stick with 5 nearest neighbors, and see how well our classifier does.
knn_fit <- knn_spec |>
fit(Class ~ ., data = train_data)
knn_preds <- predict(knn_fit, new_data = test_data)
test_data |>
mutate(predicted = knn_preds$.pred_class) |>
accuracy(truth = Class, estimate = predicted)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.971Over 97% accuracy. Not bad! Once again, pretty darn good for such a simple technique.
As a footnote, you might have noticed that Brittany Wenger did even better. What techniques did she use? One key innovation is that she incorporated a confidence score into her results: her algorithm had a way to determine when it was not able to make a confident prediction, and for those patients, it didn’t even try to predict their diagnosis. Her algorithm was 99% accurate on the patients where it made a prediction – so that extension seemed to help quite a bit.